图片Editor 分析
tui.image-editor
Full-featured photo image editor using canvas
mini画板
这个一直在更新,是可以使用的工具。使用npm和js进行管理
WebGL Filter

python 和js写的
fabric-js-editor
这个就是现在需要的针对图片和文字编辑的开源组件。他使用的是Fabric.js
Fabric.js
在这个网站上有很多针对网站的实现的内容,研究清楚这个可以直接进行编辑。
https://github.com/aurbano/nuophoto
这个实现的一般般
PlantUML Editor
https://github.com/kkeisuke/plantuml-editor
基于vue的 online UML编辑器
文档editor
https://github.com/Z-Editor/Z-Editor
https://z-editor.github.io/
A tool to create, edit and print formal Z-notation documents.
Method-Draw
非常非常好的图片Editor
yanshuo.io
用CKeditor来做的??

Markdown PPT 工具 分析
平时的文档基本上都以markdown形式进行输出,markdown可以导出到blog, gitbook, jekyll等等模型中。那么同时markdown也可以直接生成为对应的PPT,在平时讲解的时候方便直接进行投屏讲解。减少很多的制作PPT需要花费的时间。这里主要整理当下比较流行的markdown模式的ppt工具
nodeppt
nodeppt 2.0 基于webslides、webpack、markdown-it、posthtml 重构,新效果。
其中webslides使用
使用npm进行部署,所以安装和使用非常简单,只有2条命令就可以发布markdown到PPT模式。
支持的翻页效果较多,行列式也较多,整体的PPT样式看上去是很不错的。
同时支持echarts、流程图 mermaid,数学符号 KaTeX 三个插件
相关文档支持也比较好
webslider
webslider
是刚才nodeppt的基础包。这个做出来的东西设计感很强,可以点击这里看一下他的demo
但是使用起来是使用XML的模式进行写作,从markdown调整过来会比较复杂。
Marp
marp
是一个基于electron框架开发的PPT工具,所以支持多个端。最终还是到网页上进行显示
他是直接使用markdown在marp工具上进行写作。
marp当前是第二个版本,版本还在开发中,还不是很成熟。
R markdown
文档比较详实,
slides
这个是做的比较好的基于reveal.js的在线幻灯片制作工具。非开源的
https://github.com/briancavalier/slides
https://slides.com
reveal.js
strut2
https://github.com/tantaman/Strut
非常好的基于3D的带编辑器的幻灯片制作工具
wtf-slides
感觉一般般 ,但是可以学习一下代码
matrix
matrix
有时间可以研究一下这个,用的几个包还是很不错的
md2googleslides
最后生成google slides
怎么做好PPT
做好PPT的5个方向
Treat your audience as king 听众是上帝
减少灌输,更多的给听众他需要的内容,使用更易懂的沟通模式。
Spread ideas and move people
较少平白的讲解,图片可以适当的活动,产品的弹出可以加一个突然的动作,以及一些动态的小视频。吸引听众对PPT的注意,需要动态的东西。
Help them see what you are saying
让大家看到你所说的
- 人的思维分为两种,思考者和观察者,让思考者去听和思考,让观察者去观察。所以需要在演讲和PPT两方面去做
- 使用最少的文字表达你的意思,尽量使用图,减少文字,过多的文字会让听众从你的语言上分心去阅读。
- 使用脑图更好的表达意思。让听众接受你的思维方式,让你和听众能够有一个一致的思维方式。
- 将文字改为图片、表格或者图形,更容易吸引人。
Pratcice design, not decoration
- 90% 以上的设计都是破坏性的
- 需要有一个主要要点。每次只显示一个观点,不要把所有的东西一次推给听众。 缩放图片,使其占满幻灯片。删掉不需要的东西
Cultivate healthy relationships 和幻灯片培养健康的关系
- 放手幻灯片,不要隐藏在幻灯片后面
- 打破对幻灯片的依赖,让你和听众做好准备
- 将文字尽量减到最少,只显示关键的字
- 然后不停的练习、练习、练习,思考如何和幻灯片的内容结合,最后可以直接面对观众去演讲。让你和观众有眼生的交流和互动
做好PPT的前期建议
在讲述之前,首先明确几个事情
- 你跟谁在沟通?——和你的受众保持共识
- 希望你的受众了解哪些内容或者做什么? —— 明确希望受众如何反应,并考虑你的沟通方式以及调整基调
- 如何表达自己的观点?
了解你的对象
你的受众
你的受众越具体,你就越能成功地进行沟通。
一次性尝试与太多需求不同的人沟通,远没有与细分的一部分受众沟通高效。
你对受众了解得越多,就越能准确理解如何与之产生共鸣,如何在沟通中满足双方的需求。
你自己
思考你与受众的关系以及你期望他们如何看待你是非常有帮助的。
现场演讲的建议
- 写下每页幻灯片的重点。
- 大声讲给自己听。这有利于激活大脑半球,从而帮助你记住演讲的重点。这还能迫使你练好幻灯片之间的承接词,避免像其他人一样卡壳。
- 在朋友或同事面前做一次模拟演讲。
简洁的幻灯片用于现场演示(因为你会在现场详细地解释一切),详实的文档则留给受众自行消化。
三分钟故事
三分钟故事就是:如果你只有三分钟的时间把必要的信息告诉受众,你会讲什么?这是确保你对所要讲的故事理解得清晰透彻的好办法。 ——摆脱幻灯片的好办法
三要素:
- 必须能陈述你独特的观点
- 必须切中要害
- 必须是一个完整的句子
故事版——思维导图
打算创建内容的可视化大纲,它能确立沟通的结构,是打算创建内容的可视化大纲
可以使用故事版来描述,也可以使用思维导入来描述
不要从幻灯片软件开始。很容易还没想清楚如何组织各个部分就陷入到制作幻灯片的模式中去,最终只留下一套臃肿却言之无物的幻灯片。

PPT的使用
颜色的选型
少既是多
根据显示方式来选型
开哪些窗口
选择窗格 —— 图层模式,开启选择窗口适合将哪些显示,哪些隐藏,已经相应的图层顺序 。 类似PS等大多数制图软件。
动画窗格 —— 编辑动画用,基本上所有的动画都在动画窗格可以设计。
在屏幕足够大的时候,建议使用这两个窗格。可以制作大多数的动画效果。
图层的使用
组合的使用
动画的使用
- 多看——别人是怎么玩的
- 多想——结合自己的使用
图片的选择
- 尽量使用PNG图片
- 查找图片的方式
- 尽量使用高清图,最后可以压缩图片
母版
每个PPT前都需要整理的
注意事项
两种不同形式的PPT
查看型PPT
- 尽量多以图表、标题、图片形式去讲述
- 必要的文字描述可以放在备注中
- 可以直接画一些框架模块图
- 颜色可较丰富
- 较少的动作,方便PDF形式表述
讲述型PPT
- 减少颜色,准确的是减少色系
- 减少页面元素,突出重点
- 可以用动作来吸引注意,使用动作来帮助理解
- 增加视频内容
- 少用文字,将文字变为图表、图片的形式
- 结合脑图
模板的使用
图表、图标
PPT、Prezi和Snow
PPT —— 线性的讲述模式,现在大多数ppt的模式给人以一种线性的思维定型模式。其实PPT式可以支持多种模式的,但是大多数的模板以及一般的思维都将PPT固定为一种线性模式了,一篇到另一篇都是一个线性的结果。
Prezi —— Prezi的特点是缩放用户界面,在演讲过程中可以根据进程放大缩小。总的来说prezi是一个二维结构,可以缩放、旋转、无边界、在线编辑、实时保存、简单易用。
参考两个得奖Prezi
malmaison-hotel
Strut —— Strut实际上是一个三维空间的ppt,可以有x、y、z三个轴,来进行三维的跳动,从而能够给予更多一维的空间,同时也赋予了一定的prezi的缩放、旋转、无边界功能(但是这几个功能缺失没有Prezi做的强大)。另一个突出点就是Strut不需要客户端,直接在浏览器端制作,浏览器端播放,随时随地能够查看。
附件
配色网站
adobe配色网站
www.colourlovers.com
图片素材站
google image
unsplash
花瓣
阿里图标库
免费资源站
百度网盘
颜色分析功能
https://www.canva.com/colors/color-meanings/
一共有121个带有情感的颜色分析,算是比较全的颜色分析网站了,可以
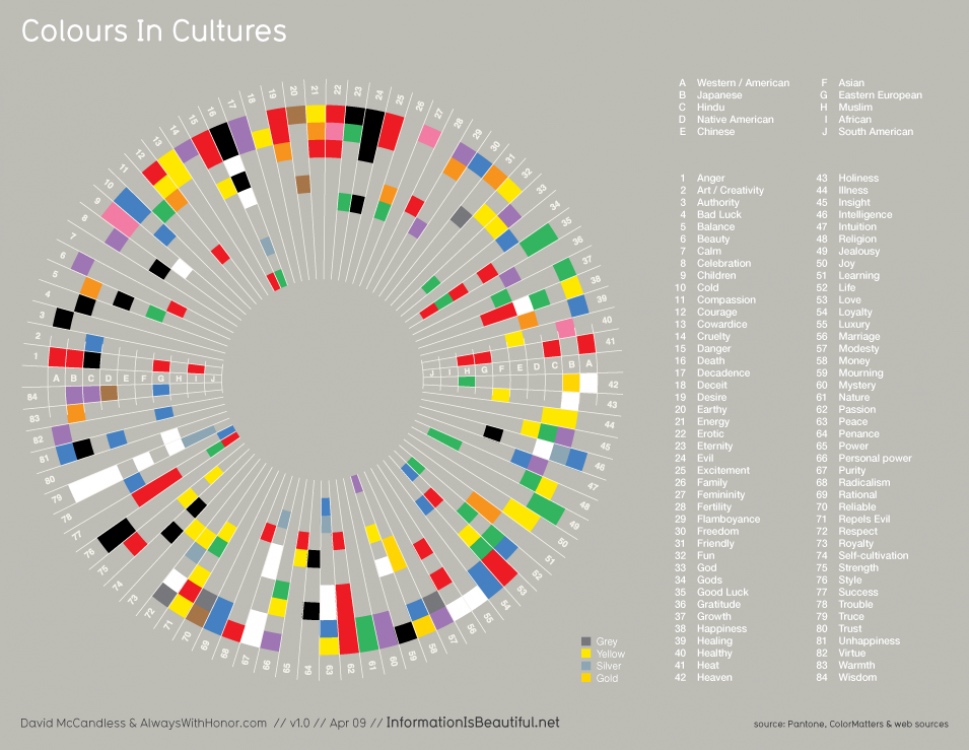
https://visual.ly/community/infographic/other/what-colors-mean-different-cultures
各个国家的颜色情感图,感觉很多,但是实际上颜色比较少
https://graf1x.com/color-psychology-emotion-meaning-poster/
只有核心颜色图
https://lifehacker.com/pick-the-right-color-for-design-or-decorating-with-this-5991303

https://www.pinterest.com/pin/29203097556548552/

https://www.dailyinfographic.com/what-colors-mean-in-different-cultures-infographic
http://www.arttherapyblog.com/online/color-meanings-symbolism/#.XVmF6WT7RXg
只讲了核心颜色
https://www.pinterest.com/pin/219902394291365592/
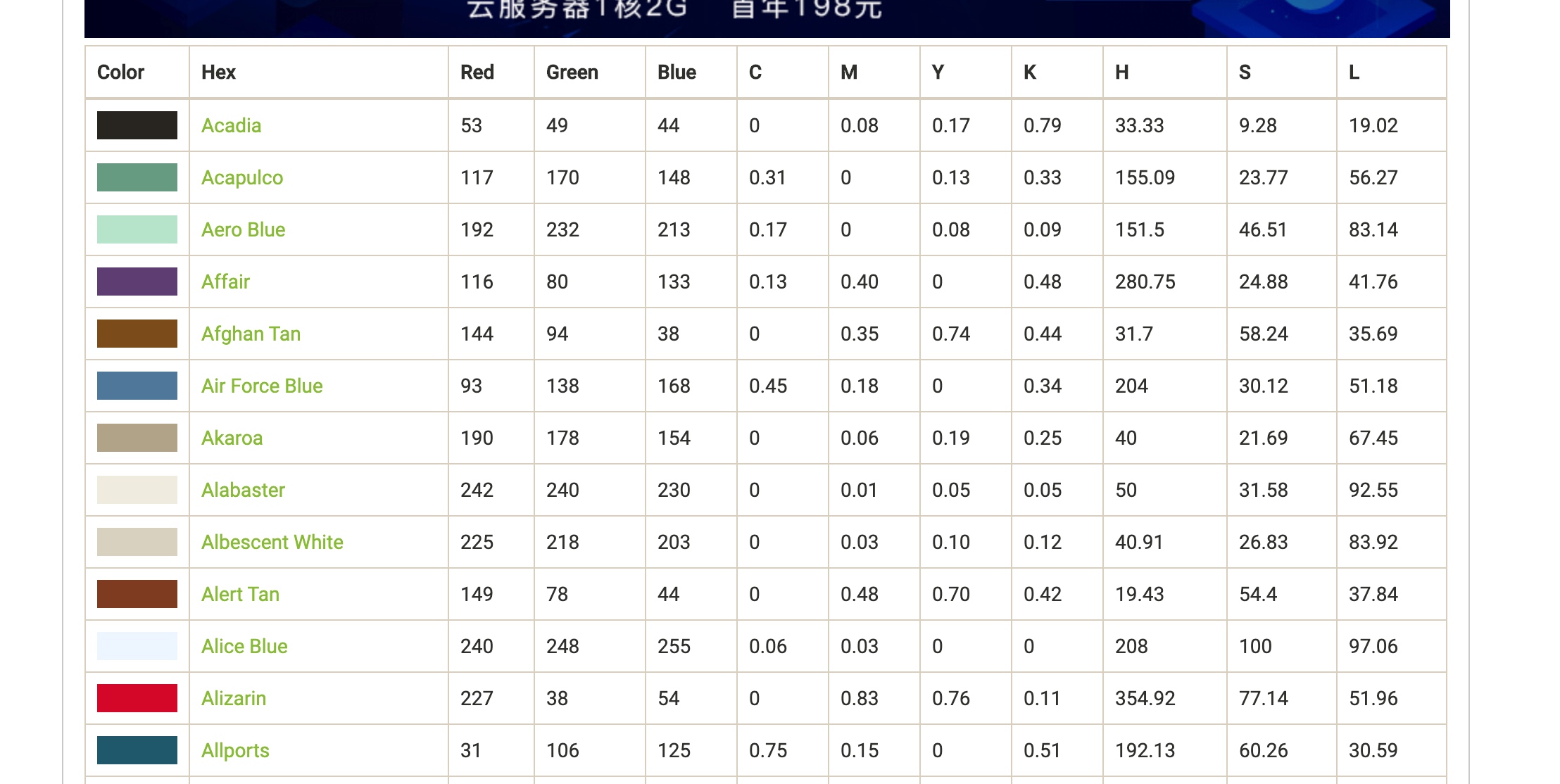
最详细的color name网页
对颜色
文档工具制作
https://github.com/phodal/2md
html转化为markdown
https://github.com/domchristie/turndown
这个是原始的网站工具
http://url2io.applinzi.com/docs
提取正文的网页服务
https://www.cnblogs.com/yetuweiba/p/4149683.html
提取网页正文的开源库的比较
https://www.cnblogs.com/jasondan/p/3497757.html
我为开源做贡献,网页正文提取——Html2Article
https://yq.aliyun.com/articles/622451
网页正文提取方法一二
https://www.yuanrenxue.com/crawler/news-crawler-content-extract.html
大规模异步新闻爬虫:网页正文的提取
https://dfkan.com/2333.html
使用API智能提取网页上的文章正文:url2io
https://www.jianshu.com/p/af5c5ef4f2f5
使用Python进行网页正文提取
http://www.elias.cn/MyProject/ExtMainText
ExtMainText —— 提取html文档正文
https://github.com/goose3/goose3
✨Python下非常好用的提取库
思维导图
[windows版本mindjet下载]http://www.ddooo.com/softdown/130314.htm
mac版本共享获取 —— 百度网盘
思维导图
心智圖(英语:Mind Map),又称脑圖、心智地圖、腦力激盪圖、思维导圖、灵感触发圖、概念地圖、或思维地圖,是一种图像式思维的工具以及一種利用图像式思考辅助工具来表达思维的工具。
心智图是使用一个中央关键词或想法引起形象化的构造和分类的想法;它用一个中央关键词或想法以辐射线形连接所有的代表字词、想法、任务或其它关联项目的图解方式。它可以利用不同的方式去表现人们的想法,如引题式,可见形象化式,建构系统式和分类式。它普遍地用作在研究、组织、解决问题和政策制定中。
心智图是一张集中了所有关连资讯的语义网路或认知体系图像。所有关连资讯都是被辐射线形及非线性图解方式接连在一起,以腦力激盪法为本去建立一个适当或相关的概念性组织任务框架。但腦力激盪法並非以制式的方式去互相连接语义网路或认知体系,亦即是可以自由相连接使用的。元素是直觉地以概念的重要性而被安排及组织入分组、分支,或区域中。会集知识方法能够支援现有的记忆,去思考语义的结构资讯。
常用思维导图软件推荐
Mindmanager
功能比较完善的思维导图工具,各个平台都有,但是觉得比较老实,界面比较老旧
xmind
做的比较好的商业导图工具
mindjet
mindjet是个人非常推荐的思维导图软件,界面比较清晰,同时操作手感比较好。最重要的是可以实现服务器端同步,将内容同步到不同的设备上。
新的版本的模板非常好,非常实用。
百度脑图
比较好用的网页版的脑图工具,方便做各个软件之间的切换。同时云端保存,更方便存放
mindjet 11版本之后支持丰富的模板供使用
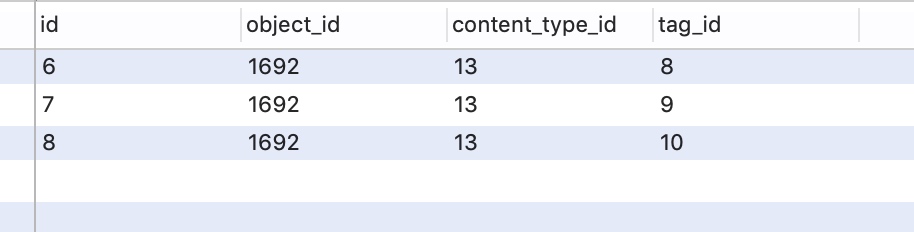
catalog目录树状图的形成
目录的树状图的django中可以使用第三方包来完善,我们可以使用django-mptt这个库来完善相应的信息
首先需要在模型中添加相应的字段,使用
from mptt.models import MPTTModel, TreeForeignKey
class TagCatalog(MPTTModel):
tag_catalog_name = models.CharField('tag_catalog_name', null=True, blank=True, max_length=255)
tag_catalog_description = models.TextField('tag_catalog_description', null=True, blank=True, max_length=255)
c_tags = models.ManyToManyField(MyCustomTag, blank=True )
parent = TreeForeignKey('self', on_delete=models.CASCADE, null=True, blank=True, related_name='tag_catalog')
class MPTTMeta:
order_insertion_by = ['tag_catalog_name']
def __str__(self):
return self.tag_catalog_name
发布模型之后,可以修改admin的内容
from mptt.admin import MPTTModelAdmin
class TagCatalogAdmin(MPTTModelAdmin):
mptt_level_indent = 20
fields = ['tag_catalog_name', 'tag_catalog_description', 'parent', 'c_tags']
list_display =('tag_catalog_name',)
filter_horizontal = ('c_tags',)
admin.site.register(TagCatalog, TagCatalogAdmin)
在views中添加相应的模型
最后在Template中添加模板就可以了
<ul>
{% recursetree tag_catalogs %}
<li>
{% if node.level == 0 %}
<h4 class="widget-title">{{ node.tag_catalog_name }}</h4>
{% elif node.level == 1 %}
<h6>{{ node.tag_catalog_name }}</h6>
{% else %}
{{ node.tag_catalog_name }}
{% endif %}
{% if not node.is_leaf_node %}
<ul class="children">
{{ children }}
</ul>
{% endif %}
</li>
{% endrecursetree %}
Django分页的实现
这篇博客非常好的详述了django分页的自定义修改方法
发表于 2018-01-23 | 分类于 Django |
可以通过 Django 提供的 Paginator 类来实现分页功能。也可以自定义实现分页功能。
自定义实现分页
一、原理解析
1、初始数据:
total_data: 数据集合,这是一个list,存放所有的数据。
page_size: 每页显示多少条数据。
num_page: 分页处显示页码数量。
2、分页需要使用的数据
current_page: 当前页,当前的页码。
通过 request.GET 获得:
current_page = int(request.GET.get('p'))
total_num: 数据条目总数
total_num = len(total_data)
max_page: 最大页码数
计算方法: 数据总条数除以每页显示条数,若余数等于0,最大页码数为商,否则最大页码数为商+1
getmax_page = lambda x,y: divmod(x,y)[0] if divmod(x,y)[1] == 0 else divmod(x,y)[0]+1
max_page = getmax_page(total_num,page_size)
peer_data: 每页显示数据
计算方法: 当我们定义page_size=10的时候,每页显示10条数据
第一页:0:10
第二页:10:20
以此类推…….
第n页:(n-1)x10:(nx10)
就可以推出每页显示数据的计算方法:
start = (current_page-1)*page_size
end = current_page*page_size
peer_data = total_data[start:end]
prev_page: 上一页页码
当前页小于等于1的时候,上一页为1
if current_page <= 1:
prev_page =1
else:
prev_page = current_page - 1
next_page: 下一页页码
当前页大于等于最大页时,下一页为最大页
if current_page >= max_page:
next_page = max_page
else:
next_page = current_page + 1
num_page_range: 分页区域显示页码范围
此处如果全部显示页码的话不合适,页码数太多页码就超级难看了,因此可以显示一个固定数量的页码值。
前面定义的 num_page (分页区域显示的页码数量)就在这里用到了。
如果num_page=7的话就这样显示:
1 2 3 4 5 6 7
前半区 后半区
实现逻辑如下:
1、总页数 max_page 小于最多显示页数 num_page ,显示1到总页数 max_page,此时显示的页码数量小于最多显示页数 num_page。
2、当前页 current_page 小于等于最多显示页数的一半 num_page/2,显示1到最多显示页数 num_page,当前页在前半区。
3、当前页 current_page 加上最多显示页数的一半 num_page/2 大于总页数 max_page,显示(总页数 max_page 减去最大显示页数 num_page)到总页数 max_page,当前页在后半区。
4、前后各显示最多显示页数一半,当前页在中间位置。
part = num_page/2
if max_page < num_page:
num_page_range = [i for i in range(1,max_page + 1)]
elif current_page <= part:
num_page_range = [i for i in range(1,num_page + 1)]
elif current_page + part > max_page:
num_page_range = [i for i in range(max_page - max_page_num,max_page + 1)]
else:
num_page_range = [i for i in range(current_page-part,current_page + part + 1)]
3、视图函数传给模板的变量汇总
current_page: 当前页码
peer_data: 当前页数据
prev_page: 上一页页码
next_page: 下一页页码
max_page: 最大页码数
num_page_range: 分页区域显示页码范围
4、前端模板逻辑分析
前端页面调用 Bootstrap 分页组件来显示:
<nav aria-label="Page navigation">
<ul class="pagination">
<li>
<a href="#" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
<li><a href="#">1</a></li>
<li><a href="#">2</a></li>
<li><a href="#">3</a></li>
<li><a href="#">4</a></li>
<li><a href="#">5</a></li>
<li>
<a href="#" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
</ul>
</nav>

上一页按钮
当前为第一页时,禁用左边的上一页按钮
<ul class="pagination">
{% if current_page == 1 %}
<li class="disabled">
<a href="#" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% else %}
<li>
<a href="?p={{ prev_page }}" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% endif %}
下一页按钮
当前为最后一页时,禁用右边的下一页按钮
{% if current_page == max_page %}
<li class="disabled">
<a href="#" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% else %}
<li>
<a href="?p={{ next_page }}" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% endif %}
显示页码范围
根据视图传过来的分页区域显示页码范围 num_page_range 来循环显示,并对当前页进行样式处理:
{% for p in num_page_range %}
{% if p == current_page %}
<li class="active"><a href="#">{{ p }}</a></li>
{% else %}
<li><a href="?p={{ p }}">{{ p }}</a></li>
{% endif %}
{% endfor %}
二、将分页实现为Web框架公共组件
分页的使用其实非常广泛,前面分析了分页实现的原理,这里我们将代码实现为公共组件,以后使用时就可以直接调用。
1、在app下建立py文件并自定义构建类
pager.py
#coding:utf-8
class Pagination(object):
def __init__(self, totalCount, currentPage, perPageItemNum=10, maxPageNum=7):
# 数据条目总数
self.total_count = totalCount
# 当前页页码值
self.current_page = currentPage
# 每页显示数据条目数
self.per_page_item_num = perPageItemNum
# 页码区域最多显示页码数
self.max_page_num = maxPageNum
def start(self):
return (self.current_page - 1)*self.per_page_item_num
def end(self):
return self.current_page*self.per_page_item_num
@property
def num_pages(self):
'''
装饰器@property将函数的方法的调用方式转换为属性调用方式
求出总页数
'''
a,b = divmod(self.total_count, self.per_page_item_num)
if a == 0:
return a
else:
return a+1
def pager_num_page(self):
'''
分页区域显示页码范围
'''
part = self.max_page_num/2
if self.num_pages < self.max_page_num:
return range(1,self.num_pages+1)
elif self.current_page <= part:
return range(1,self.max_page_num+1)
elif self.current_page + part > self.num_pages:
return range(self.num_pages-self.max_page_num,self.num_pages+1)
else:
return range(self.current_page-part,self.current_page+part+1)
def page_str(self):
'''
html返回到templates,templates中需引入bootStrap的css样式
'''
page_list = []
first = """
<li><a href='?p=1'>首页</a></li>
"""
page_list.append(first)
if self.current_page == 1:
prev_page = """
<li class="disabled">
<span>
<span aria-hidden="true">«</span>
</span>
</li>
"""
else:
prev_page = """
<li>
<a href="?p=%s" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
""" %(self.current_page - 1)
page_list.append(prev_page)
for i in self.pager_num_page():
if i == self.current_page:
temp = """
<li class="active">
<li class="active"><a href="#">%s</a></li>
</li>
""" %i
else:
temp = """
<li>
<a href="?p=%s">%s</a>
</li>
""" %(i,i)
page_list.append(temp)
if self.current_page == self.num_pages:
next_page = """
<li class="disabled">
<span>
<span aria-hidden="true">»</span>
</span>
</li>
"""
else:
next_page = """
<li>
<a href="?p=%s" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
""" %(self.current_page + 1)
page_list.append(next_page)
last = """
<li><a href='?p=%s'>尾页</a></li>
""" %self.num_pages
page_list.append(last)
return ''.join(page_list)
2、调用 Pagination 实现分页
视图方法逻辑: views.py
#coding:utf-8
from django.shortcuts import render
from app01.pager import Pagination
# 定义后台数据
mylist=[]
for i in range(1,1000):
temp = {'id':i,'name':'zhang'+str(i),'age':i,'addr':'gaoxin'+str(i),'score':2*i +1}
mylist.append(temp)
def mypager(request):
try:
current_page = int(request.GET.get('p'))
except:
current_page = 1
page_obj = Pagination(len(mylist),current_page,15,5)
data = mylist[page_obj.start():page_obj.end()]
return render(request,'mypager.html',locals())
模板使用: mypager.html
<!DOCTYPE html>
<html lang="en">
{% load staticfiles %}
<head>
<meta charset="UTF-8">
<title>mypager</title>
<link rel="stylesheet" href="{% static 'css/bootstrap.css' %}">
</head>
<body>
<div class="container">
<div class="panel">
<table class="table table-striped">
<tr>
<th>ID</th>
<th>name</th>
<th>age</th>
<th>addr</th>
<th>score</th>
</tr>
{% for item in data %}
<tr>
<td>{{ item.id }}</td>
<td>{{ item.name }}</td>
<td>{{ item.age }}</td>
<td>{{ item.addr }}</td>
<td>{{ item.score }}</td>
</tr>
{% endfor %}
</table>
</div>
<nav aria-label="Page navigation">
<ul class="pagination">
{{ page_obj.page_str | safe }}
</ul>
</nav>
</div>
</body>
</html>
完后会效果如下:

使用Django内置分页
Django提供了两个新的类(Paginator和Page)来帮助你管理分页数据,这两个类存放在 django/core/paginator.py .它可以接收列表、元组或其它可迭代的对象。
1、语法解析
Paginator类
基于分页对象
count 数据总个数
num_pages 总共可分页数
page_range 总页数索引范围
Page类
基于分页对象中的某一页
object_list 分页对象的元素列表
number 分页对象的当前页值
has_next 是否有下一页
next_page_number 下一页代码
has_previous 是否有上一页
previous_page_number 上一页代码
has_other_pages 是否有其他页
start_index 分页对象元素的开始索引
end_index 分页对象元素的结束索引
2、基本语法实例
import os
from django.core.paginator import Paginator
objects = ['john','paul','george','ringo','lucy','meiry','checy','wind','flow','rain']<br>
p = Paginator(objects,3) # 3条数据为一页,实例化分页对象
print p.count # 10 对象总共10个元素
print p.num_pages # 4 对象可分4页
print p.page_range # xrange(1, 5) 对象页的可迭代范围
page1 = p.page(1) # 取对象的第一分页对象
print page1.object_list # 第一分页对象的元素列表['john', 'paul', 'george']
print page1.number # 第一分页对象的当前页值 1
page2 = p.page(2) # 取对象的第二分页对象
print page2.object_list # 第二分页对象的元素列表 ['ringo', 'lucy', 'meiry']
print page2.number # 第二分页对象的当前页码值 2
print page1.has_previous() # 第一分页对象是否有前一页 False
print page1.has_other_pages() # 第一分页对象是否有其它页 True
print page2.has_previous() # 第二分页对象是否有前一页 True
print page2.has_next() # 第二分页对象是否有下一页 True
print page2.next_page_number() # 第二分页对象下一页码的值 3
print page2.previous_page_number() # 第二分页对象的上一页码值 1
print page2.start_index() # 第二分页对象的元素开始索引 4
print page2.end_index() # 第2分页对象的元素结束索引 6
3、内置分页使用实例
视图方法逻辑: views.py
#coding:utf-8
from django.shortcuts import render
from django.core.paginator import Paginator,PageNotAnInteger,EmptyPage
# Create your views here.
mylist=[]
for i in range(1,1000):
temp = {'id':i,'name':'zhang'+str(i),'age':i,'addr':'gaoxin'+str(i),'score':2*i +1}
mylist.append(temp)
def myin(request):
try:
current_page = int(request.GET.get('p'))
except:
current_page = 1
# 实例化分页对象,每页10条数据
paginator = Paginator(mylist,10)
try:
# 取对象的当前页分页对象
posts = paginator.page(current_page)
# current_page非数字时取第一页
except PageNotAnInteger:
posts = paginator.page(1)
# current_page空时取最后一页
except EmptyPage:
posts = paginator.page(paginator.num_pages)
return render(request,'inpage.html',{'posts':posts})
模板使用: inpage.html
<!DOCTYPE html>
{% load staticfiles %}
<html lang="en">
<head>
<meta charset="UTF-8">
<title>内置</title>
<link rel="stylesheet" href="{% static 'css/bootstrap.css' %}">
</head>
<body>
<div class="container">
<div class="panel">
<table class="table table-striped">
<tr>
<th>ID</th>
<th>name</th>
<th>age</th>
<th>addr</th>
<th>score</th>
</tr>
{% for item in posts.object_list %}
<tr>
<td>{{ item.id }}</td>
<td>{{ item.name }}</td>
<td>{{ item.age }}</td>
<td>{{ item.addr }}</td>
<td>{{ item.score }}</td>
</tr>
{% endfor %}
</table>
</div>
<nav aria-label="Page navigation">
<ul class="pagination">
<!--当前页分页对象如果有上一页-->
{% if posts.has_previous %}
<li>
<a href="?p={{ posts.previous_page_number }}" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% else %}
<li class="disabled">
<a href="#" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% endif %}
<!--循环显示可迭代页码范围-->
{% for p in posts.paginator.page_range %}
<!--如果是当前页,高亮显示-->
{% if p == posts.number %}
<li class="active"><a href="#">{{ p }}</a></li>
{% else %}
<li><a href="?p={{ p }}">{{ p }}</a></li>
{% endif %}
{% endfor %}
<!--当前页分页对象如果有下一页-->
{% if posts.has_next %}
<li>
<a href="?p={{ posts.next_page_number }}" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% else %}
<li class="disabled">
<a href="#" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% endif %}
</ul>
</nav>
</div>
</body>
</html>
使用Django内置Paginator可以实现分页,但分页区域显示的页码范围 page_range 默认是全部,如果页数很多,页码效果将会很差,下面介绍修改扩展Django内置分页,实现自定义分页区域显示的页码范围功能。
4、扩展Django内置分页
在视图函数中自定义一个新类,继承 django.core.paginator.Paginator 来进行扩展。
from django.core.paginator import Paginator,PageNotAnInteger,EmptyPage
class CustomPaginator(Paginator):
def __init__(self ,current_page, per_pager_num, *args, **kwargs):
# 当前页
self.current_page = int(current_page)
# 页码最大显示范围
self.per_pager_num = per_pager_num
# 继承父类Paginator的其他属性方法
Paginator.__init__(self, *args, **kwargs)
def pager_num_range(self):
if self.num_pages < self.per_pager_num:
return range(1, self.num_pages + 1)
part = int(self.per_pager_num / 2)
if self.current_page <= part:
return range(1, self.per_pager_num + 1)
if (self.current_page + part) > self.num_pages:
return range(self.num_pages - self.per_pager_num + 1, self.num_pages + 1)
else:
return range(self.current_page - part, self.current_page + part + 1)
## 调用
mylist=[]
for i in range(1,1000):
temp = {'id':i,'name':'zhang'+str(i),'age':i,'addr':'gaoxin'+str(i),'score':2*i +1}
mylist.append(temp)
def myin(request):
try:
current_page = int(request.GET.get('p'))
except:
current_page = 1
# 实例化分页对象,每页10条数据
paginator = CustomPaginator(current_page, 5, mylist, 10)
try:
# 取对象的当前页分页对象
posts = paginator.page(current_page)
# current_page非数字时取第一页
except PageNotAnInteger:
posts = paginator.page(1)
# current_page空时取最后一页
except EmptyPage:
posts = paginator.page(paginator.num_pages)
return render(request,'inpage.html',{'posts':posts})
完美解决问题。


](http://www.positivehealth.com/article/mind-matters/the-logic-of-emotion!%5B%5D(media/15661454029978/15661486510896.jpg)){kind=link}
Copyright © 2020 鄂ICP备16010598号-1