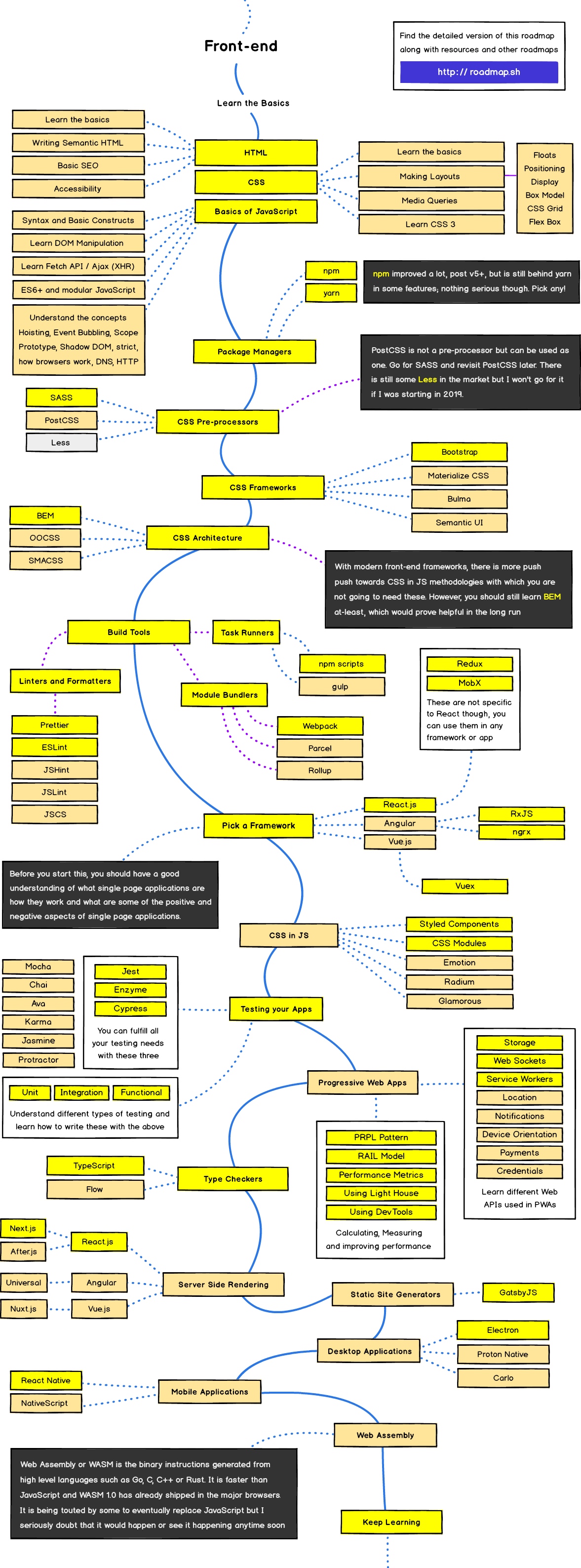
Django脚手架分析
awesome-django
cookiecutter-django
比较好的脚手架,一直在维护
代码帮助文档也比较完善,适合于研究
https://cookiecutter-django.readthedocs.io/en/latest/developing-locally.html
http://www.debugger.wiki/article/html/155222640058179
original
新一代 django 项目开发脚手架。
当你经常面临开发各种中小型项目,且需要支持微信登录、微信小程序逻辑的时候, 用这个脚手架会节省很多时间。
features
python-social-auth 提供的oauth支持, 特别对微信相逻辑定制,例如unioinid
微信小程序登录
本站 oauth, access_token 支持
简单的account逻辑
restframework
supervisor+gunicore+nginx,配置文件
cdn 图片上传,目前支持 qiniu、腾讯云
微信公众号jssdk签名
sms, 支持云片、腾讯云
图形验证码
redis 支持
二维码
cms 用户权限
适合微信开发
django-rest-pandas
Django REST Framework + pandas = A Model-driven Visualization API
Django REST Pandas (DRP) provides a simple way to generate and serve pandas DataFrames via the Django REST Framework. The resulting API can serve up CSV (and a number of other formats) for consumption by a client-side visualization tool like d3.js.
比较有意思,可以研究研究
python 日志类
Python + logging 输出到屏幕,将log日志写入文件
日志
日志是跟踪软件运行时所发生的事件的一种方法。软件开发者在代码中调用日志函数,表明发生了特定的事件。事件由描述性消息描述,该描述性消息可以可选地包含可变数据(即,对于事件的每次出现都潜在地不同的数据)。事件还具有开发者归因于事件的重要性;重要性也可以称为级别或严重性。
logging提供了一组便利的函数,用来做简单的日志。它们是 debug()、 info()、 warning()、 error() 和 critical()。
logging函数根据它们用来跟踪的事件的级别或严重程度来命名。标准级别及其适用性描述如下(以严重程度递增排序):
| 级别 | 何时使用 |
|---|---|
DEBUG |
详细信息,一般只在调试问题时使用。 |
INFO |
证明事情按预期工作。 |
WARNING |
某些没有预料到的事件的提示,或者在将来可能会出现的问题提示。例如:磁盘空间不足。但是软件还是会照常运行。 |
ERROR |
由于更严重的问题,软件已不能执行一些功能了。 |
CRITICAL |
严重错误,表明软件已不能继续运行了。 |
| 级别 | 数字值 |
|---|---|
CRITICAL |
50 |
ERROR |
40 |
WARNING |
30 |
INFO |
20 |
DEBUG |
10 |
NOTSET |
0 |
默认等级是WARNING,这意味着仅仅这个等级及以上的才会反馈信息,除非logging模块被用来做其它事情。
被跟踪的事件能以不同的方式被处理。最简单的处理方法就是把它们在控制台上打印出来。另一种常见的方法就是写入磁盘文件。
一、打印到控制台
import logging
logging.debug('debug 信息')
logging.warning('只有这个会输出。。。')
logging.info('info 信息')
由于默认设置的等级是warning,所有只有warning的信息会输出到控制台。
WARNING:root:只有这个会输出。。。
利用logging.basicConfig()打印信息到控制台
import logging
logging.basicConfig(format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s',
level=logging.DEBUG)
logging.debug('debug 信息')
logging.info('info 信息')
logging.warning('warning 信息')
logging.error('error 信息')
logging.critical('critial 信息')
由于在logging.basicConfig()中的level 的值设置为logging.DEBUG, 所有debug, info, warning, error, critical 的log都会打印到控制台。
日志级别: debug < info < warning < error < critical
logging.debug('debug级别,最低级别,一般开发人员用来打印一些调试信息')
logging.info('info级别,正常输出信息,一般用来打印一些正常的操作')
logging.warning('waring级别,一般用来打印警信息')
logging.error('error级别,一般用来打印一些错误信息')
logging.critical('critical 级别,一般用来打印一些致命的错误信息,等级最高')
所以如果设置level = logging.info()的话,debug 的信息则不会输出到控制台。
二、利用logging.basicConfig()保存log到文件
logging.basicConfig(level=logging.DEBUG,#控制台打印的日志级别
filename='new.log',
filemode='a',##模式,有w和a,w就是写模式,每次都会重新写日志,覆盖之前的日志
#a是追加模式,默认如果不写的话,就是追加模式
format=
'%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'
#日志格式
)
如果在logging.basicConfig()设置filename 和filemode,则只会保存log到文件,不会输出到控制台。
三、既往屏幕输入,也往文件写入log
logging库采取了模块化的设计,提供了许多组件:记录器、处理器、过滤器和格式化器。
- Logger 暴露了应用程序代码能直接使用的接口。
- Handler将(记录器产生的)日志记录发送至合适的目的地。
- Filter提供了更好的粒度控制,它可以决定输出哪些日志记录。
- Formatter 指明了最终输出中日志记录的布局。
Loggers:
Logger 对象要做三件事情。首先,它们向应用代码暴露了许多方法,这样应用可以在运行时记录消息。其次,记录器对象通过严重程度(默认的过滤设施)或者过滤器对象来决定哪些日志消息需要记录下来。第三,记录器对象将相关的日志消息传递给所有感兴趣的日志处理器。
常用的记录器对象的方法分为两类:配置和发送消息。
这些是最常用的配置方法:
Logger.setLevel()指定logger将会处理的最低的安全等级日志信息, debug是最低的内置安全等级,critical是最高的内建安全等级。例如,如果严重程度为INFO,记录器将只处理INFO,WARNING,ERROR和CRITICAL消息,DEBUG消息被忽略。
Logger.addHandler()和Logger.removeHandler()从记录器对象中添加和删除处理程序对象。处理器详见Handlers。
Logger.addFilter()和Logger.removeFilter()从记录器对象添加和删除过滤器对象。
Handlers
处理程序对象负责将适当的日志消息(基于日志消息的严重性)分派到处理程序的指定目标。Logger 对象可以通过addHandler()方法增加零个或多个handler对象。举个例子,一个应用可以将所有的日志消息发送至日志文件,所有的错误级别(error)及以上的日志消息发送至标准输出,所有的严重级别(critical)日志消息发送至某个电子邮箱。在这个例子中需要三个独立的处理器,每一个负责将特定级别的消息发送至特定的位置。
常用的有4种:
1) logging.StreamHandler -> 控制台输出
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。
它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler -> 文件输出
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler -> 按照大小自动分割日志文件,一旦达到指定的大小重新生成文件
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler -> 按照时间自动分割日志文件
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
配置方法:
setLevel()方法和日志对象的一样,指明了将会分发日志的最低级别。为什么会有两个setLevel()方法?记录器的级别决定了消息是否要传递给处理器。每个处理器的级别决定了消息是否要分发。setFormatter()为该处理器选择一个格式化器。addFilter()和removeFilter()分别配置和取消配置处理程序上的过滤器对象。
Formatters
Formatter对象设置日志信息最后的规则、结构和内容,默认的时间格式为%Y-%m-%d %H:%M:%S,下面是Formatter常用的一些信息
| %(name)s | Logger的名字 |
|---|---|
| %(levelno)s | 数字形式的日志级别 |
| %(levelname)s | 文本形式的日志级别 |
| %(pathname)s | 调用日志输出函数的模块的完整路径名,可能没有 |
| %(filename)s | 调用日志输出函数的模块的文件名 |
| %(module)s | 调用日志输出函数的模块名 |
| %(funcName)s | 调用日志输出函数的函数名 |
| %(lineno)d | 调用日志输出函数的语句所在的代码行 |
| %(created)f | 当前时间,用UNIX标准的表示时间的浮 点数表示 |
| %(relativeCreated)d | 输出日志信息时的,自Logger创建以 来的毫秒数 |
| %(asctime)s | 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
| %(thread)d | 线程ID。可能没有 |
| %(threadName)s | 线程名。可能没有 |
| %(process)d | 进程ID。可能没有 |
| %(message)s | 用户输出的消息 |
需求:
输出log到控制台以及将日志写入log文件。
保存2种类型的log, all.log 保存debug, info, warning, critical 信息, error.log则只保存error信息,同时按照时间自动分割日志文件。
import logging
from logging import handlers
class Logger(object):
level_relations = {
'debug':logging.DEBUG,
'info':logging.INFO,
'warning':logging.WARNING,
'error':logging.ERROR,
'crit':logging.CRITICAL
}#日志级别关系映射
def __init__(self,filename,level='info',when='D',backCount=3,fmt='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'):
self.logger = logging.getLogger(filename)
format_str = logging.Formatter(fmt)#设置日志格式
self.logger.setLevel(self.level_relations.get(level))#设置日志级别
sh = logging.StreamHandler()#往屏幕上输出
sh.setFormatter(format_str) #设置屏幕上显示的格式
th = handlers.TimedRotatingFileHandler(filename=filename,when=when,backupCount=backCount,encoding='utf-8')#往文件里写入#指定间隔时间自动生成文件的处理器
#实例化TimedRotatingFileHandler
#interval是时间间隔,backupCount是备份文件的个数,如果超过这个个数,就会自动删除,when是间隔的时间单位,单位有以下几种:
# S 秒
# M 分
# H 小时、
# D 天、
# W 每星期(interval==0时代表星期一)
# midnight 每天凌晨
th.setFormatter(format_str)#设置文件里写入的格式
self.logger.addHandler(sh) #把对象加到logger里
self.logger.addHandler(th)
if __name__ == '__main__':
log = Logger('all.log',level='debug')
log.logger.debug('debug')
log.logger.info('info')
log.logger.warning('警告')
log.logger.error('报错')
log.logger.critical('严重')
Logger('error.log', level='error').logger.error('error')
屏幕上的结果如下:
2018-03-13 21:06:46,092 - D:/write_to_log.py[line:25] - DEBUG: debug
2018-03-13 21:06:46,092 - D:/write_to_log.py[line:26] - INFO: info
2018-03-13 21:06:46,092 - D:/write_to_log.py[line:27] - WARNING: 警告
2018-03-13 21:06:46,099 - D:/write_to_log.py[line:28] - ERROR: 报错
2018-03-13 21:06:46,099 - D:/write_to_log.py[line:29] - CRITICAL: 严重
2018-03-13 21:06:46,100 - D:/write_to_log.py[line:30] - ERROR: error
由于when=D,新生成的文件名上会带上时间,如下所示。






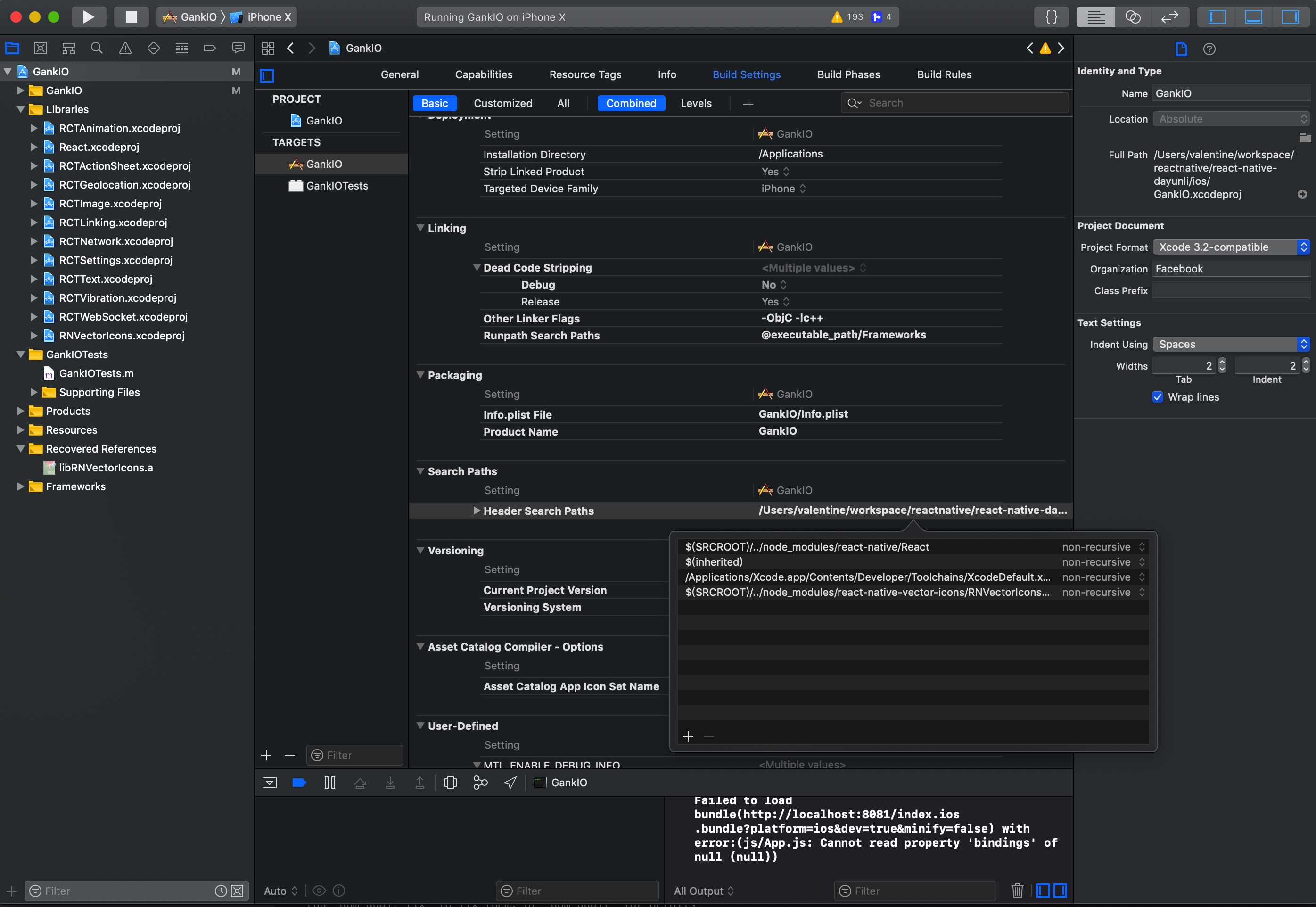
重要解决方案
Clean (cmd+shift+K)
Build core React - select React as the scheme in Xcode and build it (cmd+B)
Build the library that is failing (e.g. RCTText).
Build your app.
异常:React/RCTBridgeModule.h' file not found
首先要先把React Build一遍
https://facebook.github.io/react-native/docs/linking-libraries-ios.html
在把这里添加上react的依赖
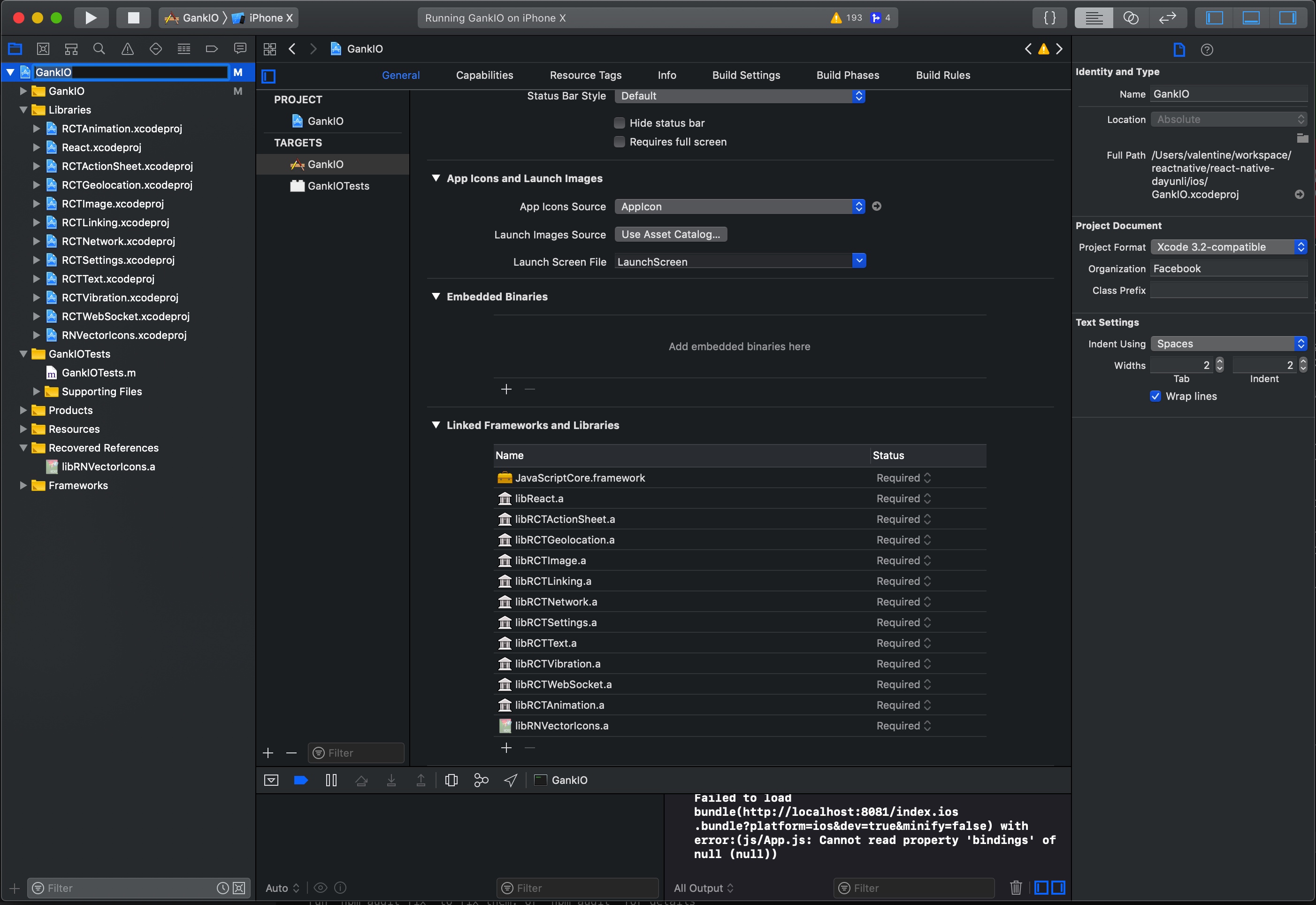
异常 Undefined symbols for architecture x86_64: "_JSClassCreate"
https://github.com/f111fei/react-native-unity-view/issues/89
这里需要添加javascript的依赖
异常 ../node_modules/react-native/packager/react-native-xcode.sh: No such file or directory
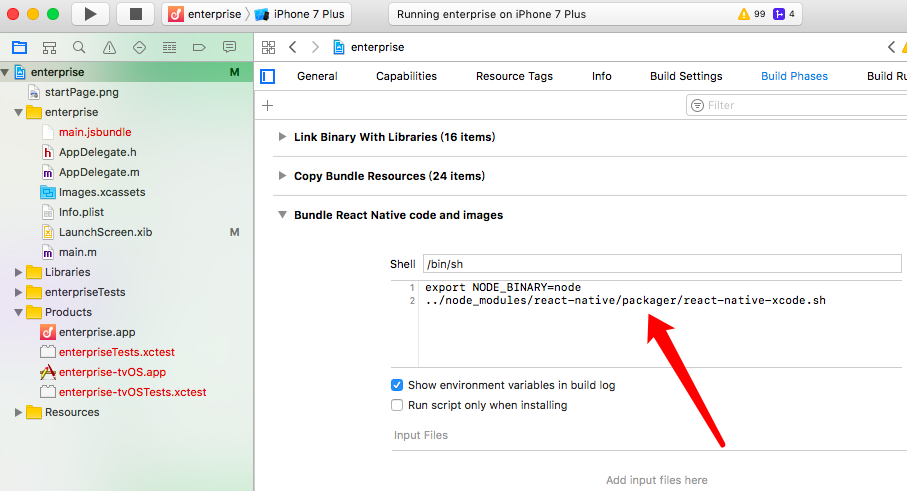
https://github.com/facebook/react-native/issues/14935
最后还是修改成scripts
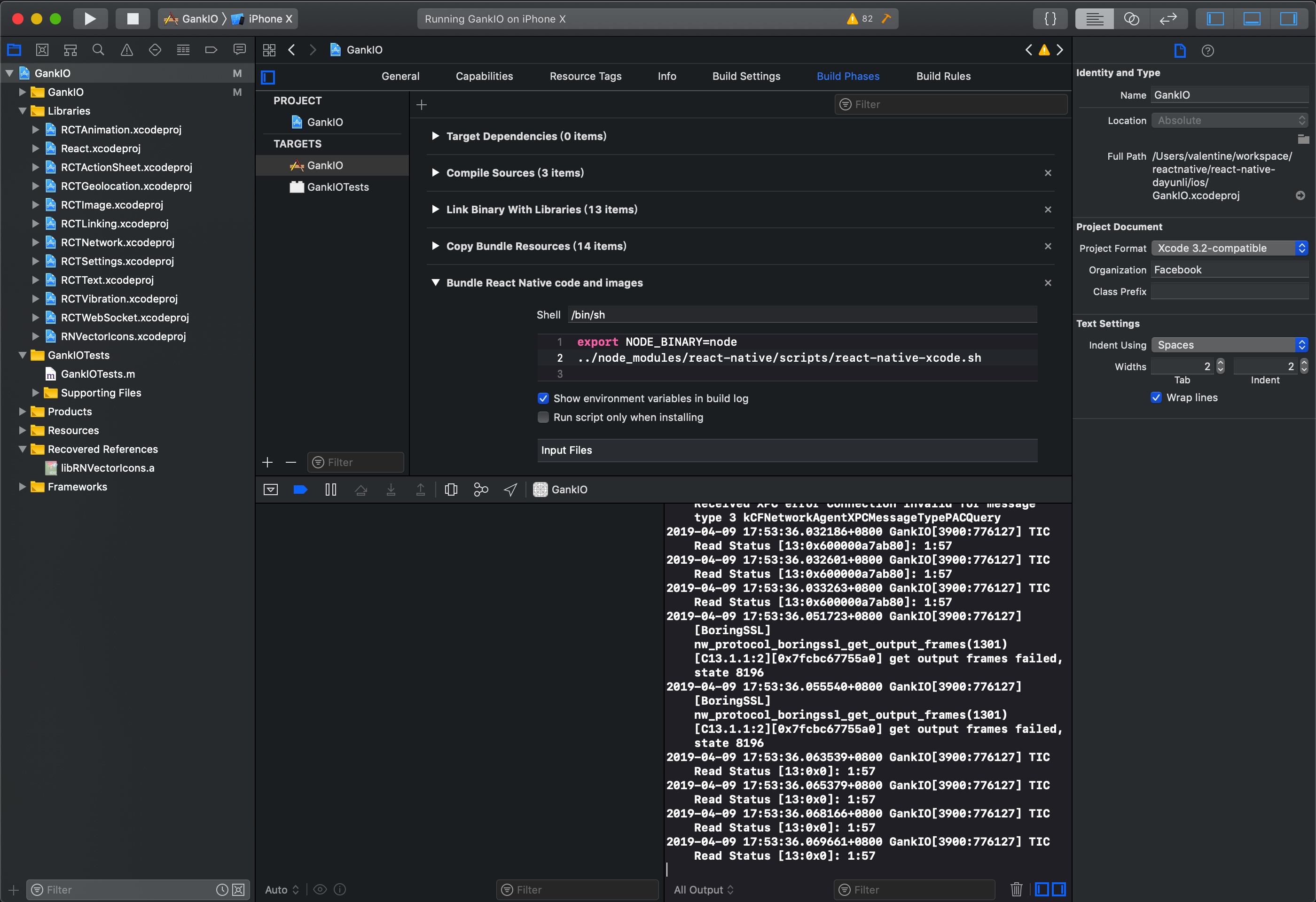
最后还是用scripts完成的。
问题:
react-native cannot read property 'bindings' of null
解决方案
https://stackoverflow.com/questions/51220030/react-native-cannot-read-property-bindings-of-null
最后是换了相关的babel包。
修改 babel
babel.rc
{
"presets": ["module:metro-react-native-babel-preset"],
"env": {
"development": {
"plugins": ["@babel/transform-react-jsx-source"]
}
},
"plugins": ["@babel/plugin-proposal-nullish-coalescing-operator"]
}
需要更新依赖:
package.json文件如下
{
"name": "GankIO",
"version": "1.0.0",
"private": true,
"scripts": {
"start": "node node_modules/react-native/local-cli/cli.js start",
"test": "jest"
},
"dependencies": {
"@babel/core": "^7.4.3",
"@babel/plugin-transform-react-jsx": "^7.3.0",
"react": "^16.8.3",
"react-native": "^0.59.4",
"react-native-deprecated-custom-components": "^0.1.2",
"react-native-root-toast": "^2.1.0",
"react-native-scrollable-tab-view": "^0.6.0",
"react-native-swipe-list-view": "^1.4.1",
"react-native-tab-navigator": "^0.3.3",
"react-native-vector-icons": "^4.6.0",
"react-redux": "^5.0.7",
"redux": "^4.0.0",
"redux-thunk": "^2.3.0",
"whatwg-fetch": "^2.0.1"
},
"jest": {
"preset": "react-native"
},
"devDependencies": {
"@babel/plugin-proposal-nullish-coalescing-operator": "^7.4.3",
"babel-jest": "23.4.2",
"babel-preset-react-native": "5.0.1",
"jest": "23.5.0",
"react-test-renderer": "16.3.1"
}
}
使用xcode进行编译
mac上可以将xcodeproj 的文件打开,然后再来进行编译,需要先编译React然后再编译Gank的话就可以成功
总结
所以可以看出来android和IOS的加载部分包还是有区别的。
要研究一下使用xcode来编译之后,那么如何debug呢
windows下C盘空间占满问题
Windows下C盘空间总是莫名其妙的占满,使用资源管理器查看C盘空间又没有很大的文件。删除的时候一般罪魁祸首在一些隐藏文件夹中。win10 会将很多数据文件写到APPData目录下,这里在windows的磁盘统计是看不到的,所以经常会出现C盘剩余空间为0,但是查看C盘文件的时候剩余几十G。当前发现的就是APPData里面的wechat缓存文件占用了40多G,导致C盘莫名其妙的没有空间了。
神奇的隐藏文件夹
有一些工具可以用来分析windows的文件系统空间,下面介绍两款:
TreeSize
Treesize,这个网站国内访问很慢,可能需要翻墙。这是找到的一个最好的文件分析查看工具,可以查看到C盘下的所有文件,分析其占用情况。
当前的问题就是使用Treesize解决的。
spacesniffer
spacesniffer是先发现的一个软件,界面和分析的结果展示的比较好看,但是并没有分析到所有的文件,就好比我说的隐藏文件没有分析出来,导致分析使用和实际使用还是有不少的差距。
后记
Win10 的C盘最好还是有100G以上,不然总会莫名其妙的空间占满。同时尽量少在windows商店里面下载软件,有时候安装的软件自己都不知道在什么地方,而且被各种权限弄得很混乱(虽然可能是为了安全着想)


scratch 分析
可以做的部分
几个可以参考的DEMO
https://scratch.mit.edu/projects/209124161/
整理一个别人做的课程清单
整理一些可以做的东西
做一个小demo
西瓜创客
159元12节课

React Native国内镜像
一、使用淘宝镜像
1.临时使用
npm --registry https://registry.npm.taobao.org install express
2.持久使用
npm config set registry https://registry.npm.taobao.org
3.通过cnpm
npm install -g cnpm --registry=https://registry.npm.taobao.org
二、使用官方镜像
npm config set registry https://registry.npmjs.org/
三、查看npm源地址
npm config get registry
Copyright © 2020 鄂ICP备16010598号-1