2018年度最受欢迎软件——中国开源软件TOP20
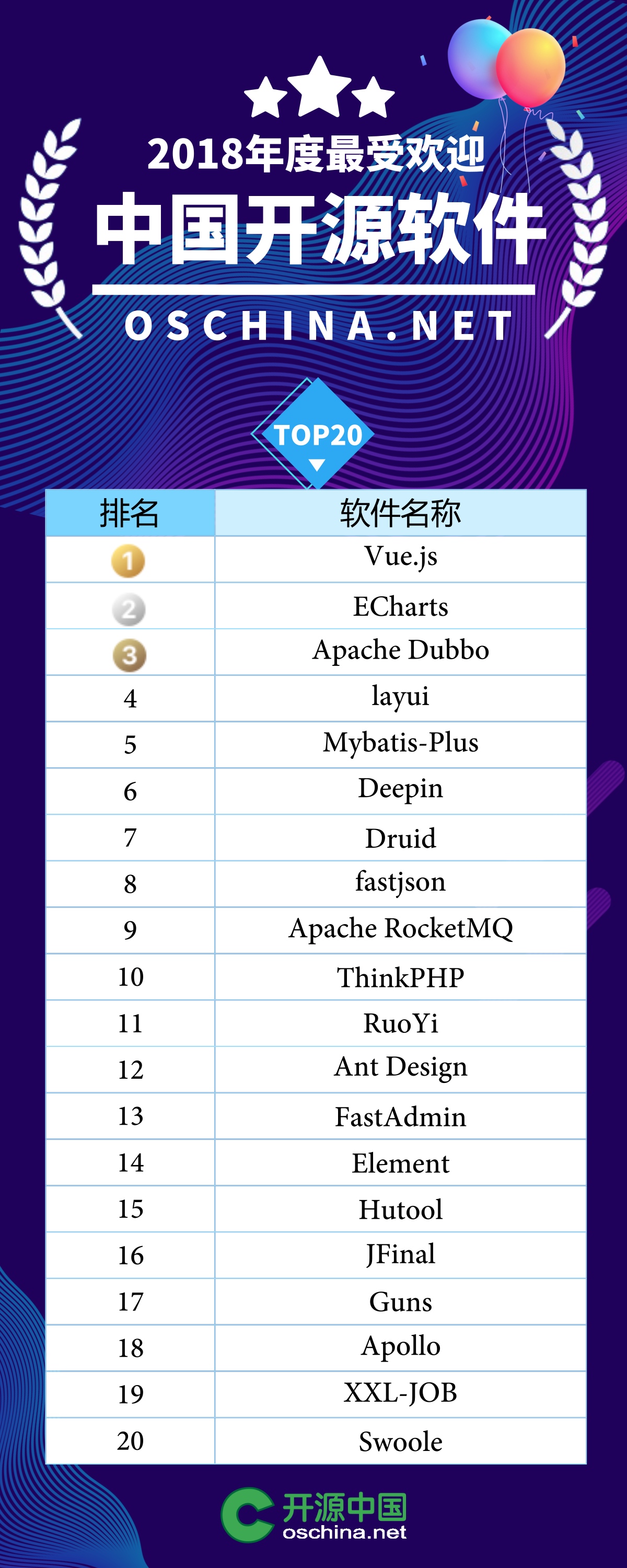
RuoYi——带代码自动生成的基于SpringBoot的管理平台
https://gitee.com/y_project/RuoYi
内置功能
用户管理:用户是系统操作者,该功能主要完成系统用户配置。
部门管理:配置系统组织机构(公司、部门、小组),树结构展现支持数据权限。
岗位管理:配置系统用户所属担任职务。
菜单管理:配置系统菜单,操作权限,按钮权限标识等。
角色管理:角色菜单权限分配、设置角色按机构进行数据范围权限划分。
字典管理:对系统中经常使用的一些较为固定的数据进行维护。
参数管理:对系统动态配置常用参数。
通知公告:系统通知公告信息发布维护。
操作日志:系统正常操作日志记录和查询;系统异常信息日志记录和查询。
登录日志:系统登录日志记录查询包含登录异常。
在线用户:当前系统中活跃用户状态监控。
定时任务:在线(添加、修改、删除)任务调度包含执行结果日志。
代码生成:前后端代码的生成(java、html、xml、sql)支持CRUD下载 。
系统接口:根据业务代码自动生成相关的api接口文档。
在线构建器:拖动表单元素生成相应的HTML代码。
连接池监视:监视当期系统数据库连接池状态,可进行分析SQL找出系统性能瓶颈。
Druid——阿里巴巴开源的带监控功能的JDBC数据库连接池
fastjson——阿里巴巴开源的JSON 转Java对象的包
AntDesign——AlipayUI 是蚂蚁金服针对 mobile 研发推出的一套基于 React 实现的 H5 组件库
里面有较多的DEMO,同时有较多的代码。
提供行业模板
同时提供axure和sketch下的网页设计模板,提升设计速度。
Hutools——Hutool是一个Java工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让Java语言也可以“甜甜的”。
Guns
Guns基于SpringBoot 2,致力于做更简洁的后台管理系统,完美整合springmvc + shiro + mybatis-plus + beetl!Guns项目代码简洁,注释丰富,上手容易,同时Guns包含许多基础模块(用户管理,角色管理,部门管理,字典管理等10个模块),可以直接作为一个后台管理系统的脚手架!
xxl-job
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
apollo
Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
Hybris 经验总结——2
hybris 学习总结2
Extension 内容
- 访问http://localhost:9001/platform/extensions 可以查看到当前所有的加载的Extension。
- 编译目录,在eclipse中得源文件会编译到eclipsebin目录中去,在系统环境ant中的编译会到classes目录中去,这样的好处是两个环境互相不会影响。
Data Model
- -items.xml 在每个扩展的这个文件里面可以配置数据模型,在Hybris里面我们把实体模型成为item,我们把item之间的关系定义为关系元素relation elements
- Hybris 系统会抽取所有Extension里面的*item.xml文件,并自动生成一系列的Java源文件来支持Hybris来访问这些实体。
- 由item系统自动生成的类文件基本上会进入以下三个目录中: 模型类——用于开发业务逻辑;WenService相关类——使用Restful URI来支持CRUD逻辑,当在item文件中配置了扩展平台webservice的时候才会生成;低级别的Jalo类。
item文件内容,添加一个item业务对象
<?xml version="1.0" encoding="ISO-8859-1"?>
<!--
[y] hybris Platform
Copyright (c) 2000-2013 hybris AG
All rights reserved.
This software is the confidential and proprietary information of hybris
("Confidential Information"). You shall not disclose such Confidential
Information and shall use it only in accordance with the terms of the
license agreement you entered into with hybris.
-->
<items xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="items.xsd">
<itemtypes>
<itemtype code="Stadium" generate="true" autocreate="true">
<deployment table="CuppyTrailStadium" typecode="10123" />
<attributes>
<attribute qualifier="code" type="java.lang.String" >
<persistence type="property"/>
<modifiers optional="false" unique="true"/>
</attribute>
<attribute qualifier="capacity" type="java.lang.Integer">
<description>Capacity</description>
<persistence type="property" />
</attribute>
</attributes>
</itemtype>
</itemtypes>
</items>
添加对象间关系
<relations>
<relation code="StadiumMatchRelation" localized="false" generate="true" autocreate="true">
<sourceElement type="Stadium" qualifier="stadium" cardinality="one" />
<targetElement type="Match" qualifier="matches" cardinality="many"/>
</relation>
</relations>
Hybris 经验总结——1
Hybris 数据库、端口配置文件
配置文件地址: hybris-commerce-suite-5.2.0.1/hybris_bin_platform/project.properties
可提供配置: Hybris 端口、Hybris容器配置、数据库
如果使用MySQL的话,需要自己创建数据库
MySQL配置:
db.url=jdbc:mysql://localhost/hybris?useConfigs=maxPerformance&characterEncoding=utf8
db.driver=com.mysql.jdbc.Driver
db.username=root
db.password=stella
db.tableprefix=
db.customsessionsql=SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
mysql.optional.tabledefs=CHARSET=utf8 COLLATE=utf8_bin
mysql.tabletype=InnoDB
mysql.allow.fractional.seconds=true
Hybris 组合包的问题
Hybris分为 Module(accelerator)、extension、page、组件等。
其中最大的为accelerator,这个可以理解为每个大的加速器模板。模板下面为extension,每一个extension为一个类似插件的形式进行扩展,一个accelerator可以包含多个extension。
每个extension都含有 project.properties和extensioninfo.xml 两个配置文件。
- project.properties配置每个extension的spring文件位置,url相关地址等extension相关规格。
- extension.info配置模块间的引用关系
local.properties 全局配置文件,用于配置全局参数,这个文件会覆盖每个extension里面的配置,所以一般把数据库连接,tomcat配置等配置在这里。
localextensions.xml
系统的Initialization 和 Update
Initialization发生时:系统将会重建、所有的数据库信息将会重建、数据模型将会重建、建立新的数据库、之前的数据模型将会删除。
Update发生时:数据库将会更新到新的模型,数据不会丢失,将在数据库中添加新的定义类型,
Extension概念
- 用自己的数据模型和商务逻辑开发一个新的工程,不用于添加代码,提供更加方便的代码重用和整合到最新的版本
- Extension可以提供下面集中类型的扩展:business logic、Data model definition、web application。
- 新创建的extension默认不被其他的extension引用,除了platform以外
- extension的优势:方便整合和更新。
- extension之间可以互相依赖,但是不能循环依赖。
- 所有的extension默认依赖于平台
- 每一个extension默认是一个Eclipse工程
- 通过extensioninfo.xml来配置extension之间的依赖关系
- 对于bean的定义有三种定义:global-{ext-name}.xml 、 {ext-name}-spring.xml 、web-application-config.xml。其中配置在global中的bean会被所有的extension共享,配置在ext-name-spring中的bean同样也会被所有的extension共享同时对不同的租户会创建不同的实例;配置在web-application-config中的bean只对所选中的extension和tenant使用。
Mac下启动Hybris
导入环境变量
PLATFORM_HOME=pwd
export -p PLATFORM_HOME
export -p ANT_OPTS="-Xmx200m -XX:MaxPermSize=128M"
export -p ANT_HOME=\(PLATFORM_HOME/apache-ant-1.9.1
chmod +x "\)ANT_HOME_bin_ant"
export -p PATH=\(ANT_HOME/bin:\)PATH
启动Hybris服务器
sh hybriserver.sh
各大Portal
- page - http://whantrade1.com:9001/yb2bacceleratorstorefront/
- hac - http://127.0.0.1:9001/
- hmc - http://127.0.0.1:9001/hmc
- cms - http://whantrade1.com:9001/cmscockpit/
- mcc - http://whantrade1.com:9001/mcc/
使用当前域名可以进入到当前网站下的配置页面,使用127.0.0.1配置的为全局页面。
环境整理
把Ant换成 1.9 版本。
页面 —— structure*Template 页面模板
项目创建
- 新建一个module,module可以视为很多个accelerator的集合。创建Module(Accelerator)使用 ant modulegen,创建Extention的时候使用 ant genext.
- 创建完成之后可以修改相应的模块依赖,将Hybris目录下面的sampleconfigurations 中得配置文件拷贝到config目录下面的localextensions.xml文件中。然后将自己创建的extension添加到相应的extension中。
- 这里一定要注意的是一定要删除重复的accelerator extesion。否则进行ant clean all的时候会报错。
- 使用ant clean all进行重新发布。
- 发布之后可以修改item文件,修改item文件的目的是创建一个数据库持久化对象,并能对这个对象自动生成很多方法
- item中得itemtype分为两种,一种是自动生成新表的,可以加上
<deployment table="OrganizationOrderStats" typecode="6214"/>,另外一种是可以生成在系统本身有的表里面的,不带这个字段。 - 添加完成itemtype之后Update一下即可。
item代码如下
<itemtype code="WilliamForTestItemProduct" extends="VariantProduct"
autocreate="true" generate="true"
jaloclass="org.training.core.jalo.WilliamForTestItemProduct">
<description>William Test Powertools size variant type that contains additional attribute describing variant size.
</description>
<attributes>
<attribute qualifier="size" type="localized:java.lang.String"
metatype="VariantAttributeDescriptor">
<description>Size of the product.</description>
<modifiers/>
<persistence type="property"/>
</attribute>
</attributes>
</itemtype>
- 修改core下面的hmc.xml
修改代码如下:
<explorertree mode="append">
<group name="user" expand="false" description="group.user.description">
<typeref type="WilliamForTestItemProduct" description="type.WilliamForTestItemProduct.name"/>
</group>
</explorertree>
9.hmc提供两种修改方式,一种是通过自己generator一个extension来创建一个工程,然后在里面修改。另外一种方式是直接在Core的hmc里面直接修改。 hmc当前只支持单表的查询,如果需要支持多表查询则必须进行扩展。 hmc页面的总hmc-configuration选项是集合了所有的hmc文件的内容,实际上hmc的机制就是这样。
Product
ProductModel baseProduct
VariantProductModel 封装了baseProduct在里面
多语言支持在数据库的响应字段后面增加一个后缀为ip的数据库表 参考 productsip
ecache 缓存机制,看看是不是写到内存里面去了,不然的话肯定会慢。
itemtype里面可以增加多语言属性 增加一个type=localized:java.lang.string
itemtype 里面, 产品层级 BaseProduct —— WFJStyleVarientProducts —— WSJCounterVariantProduct
可以在varient 里面定义多级从而来定义产品的层级。
Catagory 把产品化类别
Catalog 绑定用户权限的东西, 作为最顶级的对象。 网站的用户级别。
Catagory 绑定下面的产品结构,网站的类目级别。
Classification 属性系统
classification 系统, 所有的商品属性组都是按照classification来做,如果把Product和Classification切断之后,Product就没有任何属性了。
在Classification中定义属性,这些属性还可以有继承关系。
产品价格 Price Rows price setting中
定义一个价格的有效期、范围。
产品 吊牌价、真实价格。
一个产品可以关联很多个price row , 真正起作用的根据关联属性,根据真是价格关联到Price Row。
一般都是一个产品对应一个或多个PriceRow,但是基本不会出现多个产品对应一个PriceRow的,根据业务需求来。
价格可以设置时间段来判断相应的价格。
权限的功能,在用户的后面添加一个select语句就可以进行相关权限限制。
HMC 开发
webchart 的开发元素
https://wiki.hybris.com/display/release5/How+To+Write+an+hMC+Editor+WebChip
https://wiki.hybris.com/display/release5/How+To+Create+a+Wizard
在hmc上面做一个excel导入的方法,让客户使用excel的方式导入产品。
联表查询
定制化显示字段
鼠标右键动态开发
ImpExImportJob 这个可以用于用代码导入Impex文件。
https://wiki.hybris.com/display/accdoc/B2C-Specific+Accelerator+Extensions
https://wiki.hybris.com/display/release5/Classification+Guide
https://wiki.hybris.com/display/release5/Modeling+Product+Variants
https://wiki.hybris.com/display/release5/Restrictions
https://wiki.hybris.com/display/forum/User+Rights+Import
https://wiki.hybris.com/display/release5/How+To+Create+a+Wizard
https://wiki.hybris.com/display/accdoc/B2C-Specific+Accelerator+Extensions
hybris日志
platform 实际上是一个tomcat
查数据
一般是使用flaxibleSearch 来用代码查询数据
查询基本上全部都是使用这种方式来实现的。
提供一个单例的转换模式,使用DAO 查询DTO之后,使用一个单例的转换模式,然后转换成自己建的bean,用于页面展现。
用户密码可以自己做一套加密的算法和老系统保持一致,在添加用户的时候可以看到
PasswordEncode 类用于密码加解密。如果需要在HMC里面显示的话,需要做一次配置,在spring.xml里面配置,配置一个bean,用于专门的加密,持久化到数据库。
页面
cms2 Data model overview
cms2 Extension Tutorial
base store ---- website
cmscockpit 进入修改页面,使用自己的域名进去
首页位置
_Users_valentine_workspace_hybris-commerce-suite-5.5.0.0/hybris_bin_custom_training_trainingstorefront_web_webroot__ui_desktop
页面模板的位置
_Users_valentine_workspace_hybris-commerce-suite-5.5.0.0/hybris_bin_custom_training_trainingstorefront_web_webroot_WEB-INF_views
页面怎么做
https://wiki.hybris.com/display/release5/cms2+Extension+Tutorial
页面框架图
https://wiki.hybris.com/display/release5/cms2+-+Data+Model+Overview
如何增加一个新的CMS组件
https://wiki.hybris.com/display/release5/How+to+Add+a+New+CMS+Component
WCMS组件信息
https://wiki.hybris.com/display/accdoc/WCMS+Components
WCMS是一个编辑环境, 所有的展示东西都是模板里面,在WCMS改得时候
主页生效要在WCMS里面把生效点一下。
wiki : WCMS components 可以看到所有的组件接口
页面组件数据都是可以在jsp里面修改的,具体的进去搜索 navigatebar*.jsp
导入数据入口类
_Users_valentine_workspace_hybris-commerce-suite-5.5.0.0/hybris_bin_custom_training_traininginitialdata_src_org_training_initialdata_setup_InitialDataSystemSetup.java
_Users_valentine_workspace_hybris-commerce-suite-5.5.0.0/hybris_bin_custom_training_trainingcore_src_org_training_core_setup_CoreSystemSetup.java
自己的做法:
自己项目下面的,新建一个工程,自己写初始化类(像上面定义的)归结上面要倒的数据。然后加进去
wiki : customize initialization process
页面目录的内容管理:
_Users_valentine_workspace_hybris-commerce-suite-5.5.0.0/hybris_bin_ext-template_yacceleratorinitialdata_resources_yacceleratorinitialdata_import_coredata_contentCatalogs_catalogName_cms-content_zh.impex
wrapper
wrapper 把tomcat打一下,在tomcat奔溃的时候会自动重启
B2B
admincockpit 提供一个B2B admin管理方式
addonsupport
secureportaladdon
加上这两个扩展。
ant addoninstall -Daddonnames="..."
使用这个ant命令可以添加addon,实际上添加addon和普通的添加扩展是不一样的。
邮件需要配置一个邮件服务器。
注册完成之后,登陆hmc之后,在Enployment里面添加 审批 approval ,然后在admincockpit里面就可以看到审核消息。
客户核心以单位进行管理,用户必须要设置一个用户单位。
其他的cockpit使用zk的js架构去做扩展
project.properties 写入程序变量
查询
一般后台使用flexsearch查询
https://wiki.hybris.com/display/release5/FlexibleSearch
Update 和 Delete 效率比较低,插入较好。 设计的时候尽量的去做插入,少做Update和Delete。
做更新的时候,很多情况可以做两张表,一边用来做insert,然后不停的做查询。
wiki :MediaConversion
wiki 拦截器 :interceptors
https://wiki.hybris.com/display/accdoc/B2B
https://wiki.hybris.com/display/release5/Interceptors
动态多表查询 Query Hmc里面有
动态属性概念,用于多表查询的时候,把里面的某个字段(引用字段) 展示为多表之间的关系。
solr 全文检索系统,下面配置了lucene。
JVM深度剖析——垃圾收集器与内存分配策略
Jvm深度剖析
垃圾收集器与内存分配策略
几种基本垃圾收集算法:
引用计数法(Reference Counting)
- 给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻引用计数器为0就代表对象不可能再被使用的。
- 引用计数器未在Java中使用的主要原因是它很难解决对象之间的相互循环引用的问题。
根搜索算法(GC Rooting Tracing)
- 通过一系列名为"GC Routes"的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径成为引用链(Reference Chain),当一个对象到GC Roots 没有任何引用链相连时,则证明对象是不可用的。
- Java语言里,可以作为GC Roots的对象包括:虚拟机栈中引用的对象、方法区中得类静态属性引用的对象、方法区中常亮引用的对象、本地方法栈中JNI的引用对象
引用
JDK引用概念将引用分为强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)四种,这四种引用强度依次逐渐减弱。
- 强引用:在程序代码中普遍存在的引用 Object obj = new Object()。只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
- 软引用:描述一些还有用,但是非必须得对象。对于软引用关联着的对象,在系统将要发生内存溢出异常时,将会把这些对象列进回收范围之中并进行第二次回收。如果回收还是没有足够的内存,才会抛出内存溢出异常。
- 弱引用:被弱引用关联的对象只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。
- 虚引用:也称为幽灵引用或者幻影引用。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响。也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是希望能在这个对象被收集器回收时受到一个系统通知。
finalize()方法
在根搜索算法中不可达的对象,处于缓刑状态,要真正宣告一个对象死亡,至少要经历两次标记过程:第一次标记和筛选条件是对象是否有必要执行finalize()方法。当对象没有覆盖finalize()方法或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况视为“没有必要执行”。如果对象被判定为有必要执行finalize()方法,那么这个对象将会被放置在一个名为F-Queue的队列中,并稍后由一条虚拟机自动建立的,低优先级的Finalizer线程去执行。
finalize的运行代价较高,不确定性非常大,无法保证各个对象的调用顺序。finalize能做的工作,使用try-finally或其他方法可以做得更好、更及时,尽量避免使用这个方法。
回收方法区
永久代的垃圾收集主要回收两个部分:废弃常量和无用的类。
废弃常量: 当系统中没有任何一个对象引用此常量,就会被系统请出常量池
无用的类: 1.该类所有的实例都已被回收,也就是Java堆中不存在该类的任何实例。2.加载该类的ClassLoader已经被回收。3.该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
是否进行类回收,HotSpot虚拟机提供了-Xnoclassgc参数进行控制。
-Xnoclassgc 禁用class垃圾收集
-verbose:class -XX:+TraceClassLoading、-XX:+TraceClassUnLoading查看类的加载和卸载信息。
在大量使用反射、动态代理、CGLib等bytecode框架的场景,以及动态生成JSP和OSGI这类频繁自动以ClassLoader的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
垃圾收集算法
标记-清除算法
首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
缺点:一是效率问题,标记和清除过程效率不高。二是空间问题,标记和清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存空间而不得不提前触发另一次的垃圾收集动作。
复制算法
将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间依次清理掉。
缺点:内存缩小为原来的一半,代价太高。
现代商业虚拟机使用复制算法来回收新生代,对于新生代中98%的对象是朝生夕死的,不需要按照1:1的比例来划分空间,二是将内存划分为一块较大的Eden空间和两块较小的Survivor空间。每次使用Eden空间和其中一块Survivor空间。当回收时,将Eden和Survivor空间存活着的对象一次性拷贝到另外一块Survivor空间上,最后清理掉Eden和Survivor空间。
HotSpot虚拟机默认Eden和Survivor的大小比例是8:1。
如果另外一块Survivor空间没有足够的空间存放上一次新生代收集下来的存活对象,这些对象将直接通过分配担保机制进入老年代。
标记-整理算法
标记过程和标记-清除算法一样,但后续步骤不是直接对可回收对象进行清理,二是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
分代收集算法(Generational Collection)
当前商业虚拟机都使用分代收集算法。一般是把Java堆分为新生代和老年代,根据各个代的特点采用最适当的收集算法。
垃圾收集器
Serial收集器
- 单线程收集器。在垃圾收集时,必须暂停其他所有工作线程(Stop The World)。
- 现代虚拟机运行在Client模式下得默认新生代收集器。桌面应用场景中分配虚拟机内存一般只有几十到一两百兆的新生代,停顿时间可以控制在几十毫秒之内。
ParNew收集器
- Serial收集器的多线程版本。除了使用多条线程以外,其余行为包括Serial收集器可用得所有控制参数、收集算法、Stop The World、对象分配规则、收回策略等都与Serial收集器完全一样。
- 许多运行在Server模式下得虚拟机中首选的新生代收集器
- 目前只有它能与CMS收集器配合工作。
- ParNew收集器在单CPU环境下绝对不会有比Serial更好的效果。
Parallel Scavenger收集器
- 新生代收集器,使用复制算法的收集器,又是并行的多线程收集器。
- Parallel Scavenger收集器的目的是达到一个可控制的吞吐量。吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
- 提供两个参数: -XX:MaxGCPauseMills 设置最大垃圾收集停顿时间 -XX:GCTimeRatio 设置吞吐量大小
- GC自适应调节策略(GC Ergonomics) : -XX:+UseAdaptiveSizePolicy 指定不需要手工指定新生代的大小(-Xmm)、Eden和Survival(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数。虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量。
- 自适应调节是Parallel Scavenger收集器与ParNew收集器的一个重要区别。
Serial Old收集器
- Serial收集器的老年代版本。同样是一个单线程收集器,使用"标记-整理"算法。
- 在Client模式下的虚拟机使用。
- 在Server模式下:在JDK1.5之前的版本中与Parallel Scavenger收集器搭配使用,另一个就是作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure的时候使用。
Parallel Old收集器
- Parallel Scavenger收集器的老年代版本,使用多线程和"标记-整理"算法。
- 在吞吐量优先的情况下,在注重吞吐量及CPU资源敏感的场合,都可以优先考虑Parallel Scavenger加Parallel Old收集器。
CMS收集器
- CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。
- 基于"标记-清除"算法实现
- 步骤:初始标记(CMS initial mark)、并发标记(CMS concurrent mark)、重新标记(CMS remark)、并发清除(CMS concurrent sweep)。
- 初始标记、重新标记这两个步骤任然需要"Stop the World"。初始标记仅仅标记一下GC Roots能直接关联到得对象,速度很快。并发标记阶段就是进行GC Roots Tracing的过程。重新标记阶段则是为了修正并发标记期间,用户因程序继续运行而导致标记产生变动的那一部分对象的标记记录。由于整个过程中最长的并发标记和并发清除过程中,收集线程都可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发地执行的。
- 缺点: 1.对CPU资源非常敏感,会因为占用一部分线程资源导致应用程序变慢。2. 无法处理浮动垃圾,可能出现Concurrent Mode Failure失败而导致另一次Full GC 产生。3. 标记清除算法会形成大量碎片,空闲碎片过多时,将会给大对象分配带来麻烦,造成往往老年代还有很大的空间剩余,但是由于无法找到足够大的连续空间来分配对象,不得不提前触发一次Full GC。
G1收集器
- 基于标记-整理算法实现的收集器。
- 可以做到基本不牺牲吞吐率的前提下完成低停顿的回收工作。
垃圾收集参数
可以参考这篇文章 http://blog.sina.com.cn/s/blog_4080505a0101i6cr.html
MinorGC和Full GC的区别
新生代GC(Minor GC)指发生在新生代的垃圾收集动作。MinorGC非常频繁,且回收速度一般较快。
老年代GC(Major GC/Full GC)指发生在老年代的垃圾收集动作。出现了Major GC,经常会伴随着至少一次的Minor GC(但非绝对的)。MajorGC的速度一般会比MinorGC慢10倍以上。
Serial/Serial Old收集器下得内存分配和回收机制
- 对象优先在新生代Eden区中分配。当Eden区没有足够的空间进行分配时,虚拟机将发起一次MinorGC。
- -XX:+printGCDetails 这个参数收集日志参数,告诉虚拟机在发生垃圾收集行为时打印内存回收日志,并且在进程退出的时候输出当前内存各区域的分配情况。内存回收日志一般是打印到文件后通过日志工具进行分析。
- 需要大量连续内存空间的对象,就是所谓的大对象直接进入老年代。
- 大对象对虚拟机的内存分配来说是一个坏消息(比遇到一个大对象更加坏得消息是遇到一群朝生夕灭的短命大对象),写程序时应尽量避免,经常出现大对象容易导致内存还有不少空间时就提前触发垃圾收集以获取足够的连续空间来安置他们。
- 虚拟机提供一个-XX:PretenureSizeThrehold参数,另大于这个值得对象直接在老年代中分配。目的是避免大对象在Eden区和Survivor区之间发生大量的内存拷贝。
- 长期存活的对象将进入老年代。虚拟机给每个对象定义了一个对象年龄Age计数器。如果对象在Eden出生并经过第一次MinorGC后仍然存活,并且能被Survivor容纳的话,将被移动到Survivor空间中,并将对象年龄设为1 。对象在Survivor区中每熬过一此MinorGC,年龄就增加1岁,当它的年龄增加到一定程度(默认15岁)时,就会被晋升到老年代中。
- -XX:MaxTenuringThreshold来设置对象晋升老年代的年龄阈值。
- 动态年龄判定,虚拟机并不是总要求对象的年龄必须达到MaxTenuringThreshold才能晋升老年代,如果在Survivor中空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代。
- 空间分配担保(在MinorGC时如果Survivor空间无法容纳内存回收后的新生代对象,则需要老年代进行这样的担保),在发生MinorGC时,虚拟机会检测之前每次晋升到老年代的平均大小是否大于老年代的剩余空间大小,如果大于,则改为一次FullGC。如果小于,则查看HandlePromotionFailure设置是否允许担保失败,如果允许则进行MinorGC,如果不允许则进行一次FullGC。
GC 日志和参数定义
如果希望查看程序的GC日志,需要在启动参数中增加参数-verbose:gc ,这个开关用于显示GC内容。可以显示最忙和最空闲收集行为发生的时间、收集前后的内存大小、收集需要的时间等。
-XX:+printGCdetails : 输出详细GC日志,可以详细了解GC中的变化。
-XX:+PrintGCTimeStamps : 输出GC的时间戳(以基准时间的形式),可以了解这些垃圾收集发生的时间,自JVM启动以后以秒计量。
-XX:+PrintGCDateStamps : 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC : 在进行GC的前后打印出堆的信息, 了解堆的更详细的信息。
-XX:=PrintTenuringDistribution : 开关了解获得使用期的对象权。
-Xloggc:$CATALINA_BASE/logs/gc.log : gc日志产生的路径
-XX:+PrintGCApplicationStoppedTime : 输出GC造成应用暂停的时间
也可以使用一些离线工具来进行GC日志的具体分析。比如sun的gchisto,gcviewer,这些都是开源的工具,用户可以直接通过版本控制工具下载其源码,进行离线分析。
Sun 垃圾收集实现
实现代码
/**
*参数: -verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC
*/
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) {
byte[] allocation1, allocation2, allocation3, allocation4, allocation5;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
System.out.println("allocation1 = " + allocation1 + "\n allocation2 = " +allocation2 + "\n allocation3 = " + allocation3);
allocation4 = new byte[4 * _1MB]; // 此时出现一次MinorGC
//allocation1 = null;
allocation5 = new byte[2 * _1MB];
//byte[] allocation6 = new byte[6 * _1MB];
}
返回结果:
allocation1 = [B@150697e2
allocation2 = [B@2a36bb87
allocation3 = [B@4fd281f1
{Heap before GC invocations=1 (full 0):
PSYoungGen total 9216K, used 7143K [0x00000007ff600000, 0x0000000800000000, 0x0000000800000000)
eden space 8192K, 87% used [0x00000007ff600000,0x00000007ffcf9eb0,0x00000007ffe00000)
from space 1024K, 0% used [0x00000007fff00000,0x00000007fff00000,0x0000000800000000)
to space 1024K, 0% used [0x00000007ffe00000,0x00000007ffe00000,0x00000007fff00000)
ParOldGen total 10240K, used 4096K [0x00000007fec00000, 0x00000007ff600000, 0x00000007ff600000)
object space 10240K, 40% used [0x00000007fec00000,0x00000007ff000010,0x00000007ff600000)
PSPermGen total 21504K, used 2590K [0x00000007f9a00000, 0x00000007faf00000, 0x00000007fec00000)
object space 21504K, 12% used [0x00000007f9a00000,0x00000007f9c87a70,0x00000007faf00000)
2015-01-05T15:18:41.818-0800: [GC-- [PSYoungGen: 7143K->7143K(9216K)] 11239K->15335K(19456K), 0.0048480 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
Heap after GC invocations=1 (full 0):
PSYoungGen total 9216K, used 7143K [0x00000007ff600000, 0x0000000800000000, 0x0000000800000000)
eden space 8192K, 87% used [0x00000007ff600000,0x00000007ffcf9eb0,0x00000007ffe00000)
from space 1024K, 0% used [0x00000007fff00000,0x00000007fff00000,0x0000000800000000)
to space 1024K, 40% used [0x00000007ffe00000,0x00000007ffe68020,0x00000007fff00000)
ParOldGen total 10240K, used 8192K [0x00000007fec00000, 0x00000007ff600000, 0x00000007ff600000)
object space 10240K, 80% used [0x00000007fec00000,0x00000007ff400030,0x00000007ff600000)
PSPermGen total 21504K, used 2590K [0x00000007f9a00000, 0x00000007faf00000, 0x00000007fec00000)
object space 21504K, 12% used [0x00000007f9a00000,0x00000007f9c87a70,0x00000007faf00000)
}
{Heap before GC invocations=2 (full 1):
PSYoungGen total 9216K, used 7143K [0x00000007ff600000, 0x0000000800000000, 0x0000000800000000)
eden space 8192K, 87% used [0x00000007ff600000,0x00000007ffcf9eb0,0x00000007ffe00000)
from space 1024K, 0% used [0x00000007fff00000,0x00000007fff00000,0x0000000800000000)
to space 1024K, 40% used [0x00000007ffe00000,0x00000007ffe68020,0x00000007fff00000)
ParOldGen total 10240K, used 8192K [0x00000007fec00000, 0x00000007ff600000, 0x00000007ff600000)
object space 10240K, 80% used [0x00000007fec00000,0x00000007ff400030,0x00000007ff600000)
PSPermGen total 21504K, used 2590K [0x00000007f9a00000, 0x00000007faf00000, 0x00000007fec00000)
object space 21504K, 12% used [0x00000007f9a00000,0x00000007f9c87a70,0x00000007faf00000)
2015-01-05T15:18:41.823-0800: [Full GC [PSYoungGen: 7143K->2343K(9216K)] [ParOldGen: 8192K->8192K(10240K)] 15335K->10535K(19456K) [PSPermGen: 2590K->2589K(21504K)], 0.0105960 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
Heap after GC invocations=2 (full 1):
PSYoungGen total 9216K, used 2343K [0x00000007ff600000, 0x0000000800000000, 0x0000000800000000)
eden space 8192K, 28% used [0x00000007ff600000,0x00000007ff849d00,0x00000007ffe00000)
from space 1024K, 0% used [0x00000007fff00000,0x00000007fff00000,0x0000000800000000)
to space 1024K, 0% used [0x00000007ffe00000,0x00000007ffe00000,0x00000007fff00000)
ParOldGen total 10240K, used 8192K [0x00000007fec00000, 0x00000007ff600000, 0x00000007ff600000)
object space 10240K, 80% used [0x00000007fec00000,0x00000007ff400030,0x00000007ff600000)
PSPermGen total 21504K, used 2589K [0x00000007f9a00000, 0x00000007faf00000, 0x00000007fec00000)
object space 21504K, 12% used [0x00000007f9a00000,0x00000007f9c876a0,0x00000007faf00000)
}
Heap
PSYoungGen total 9216K, used 4801K [0x00000007ff600000, 0x0000000800000000, 0x0000000800000000)
eden space 8192K, 58% used [0x00000007ff600000,0x00000007ffab04b0,0x00000007ffe00000)
from space 1024K, 0% used [0x00000007fff00000,0x00000007fff00000,0x0000000800000000)
to space 1024K, 0% used [0x00000007ffe00000,0x00000007ffe00000,0x00000007fff00000)
ParOldGen total 10240K, used 8192K [0x00000007fec00000, 0x00000007ff600000, 0x00000007ff600000)
object space 10240K, 80% used [0x00000007fec00000,0x00000007ff400030,0x00000007ff600000)
PSPermGen total 21504K, used 2599K [0x00000007f9a00000, 0x00000007faf00000, 0x00000007fec00000)
object space 21504K, 12% used [0x00000007f9a00000,0x00000007f9c89e30,0x00000007faf00000)
可以根据这个了解到部分Sun Java虚拟机GC实现细节:
堆被划分成三个不同的区域:新生代 ( PSYoungGen )、老年代 ( ParOldGen )、永久代( PsPermGen)。
新生代 ( Young ) 又被划分为三个区域:
Eden、From Survivor、To Survivor。
这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。 其中的比例默认为8:1:1, 也可以使用参数修改。
新生代和老年代的比例一般为1:2, 也可以自己通过参数定义。
JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。
SUN JVM GC 使用是分代收集算法,即将内存分为几个区域,将不同生命周期的对象放在不同区域里。新的对象会先生成在Young area,也就是PSYoungGen中。在几次GC以后,如过没有收集到,就会逐渐升级到PSOldGen 及Tenured area(也就是PSPermGen)中。
PSYoungGen ParOldGen PsPermGen区别
在GC收集的时候,频繁收集生命周期短的区域(Young area),因为这个区域内的对象生命周期比较短,GC 效率也会比较高。而比较少的收集生命周期比较长的区域(Old area or Tenured area),以及基本不收集的永久区(Perm area)。
JVM深度剖析——内存溢出分析方法
Java深度剖析——内存溢出分析方法
工具
安装Memory Analyse Tools(MAT) 工具, 可以直接在eclipse中安装其相应的插件,安装方法可以参考另一篇eclipse插件汇总
不会用的可以参考一下这个帖子使用 Eclipse Memory Analyzer 进行堆转储文件分析
一些Java内存参数设置
-vmargs: 说明后面是VM的参数,所以后面的其实都是JVM的参数了
-Xms20m: Java初始分配的堆内存,此处设置为20M
-Xmx20m: Java最大允许分配的堆内存,此处设置为20M,同时这样设置表示堆内存不许扩展
-XX:PermSize=64M: JVM初始分配的非堆内存
-XX:MaxPermSize=128M: JVM最大允许分配的非堆内存,按需分配
-XX:+HeapDumpOnOutOfMemoryError: 让虚拟机在出现内存溢出异常时dump出当前内存堆转储快照以便事后进行分析。
带上这种参数之后运行Jvm,如果出现相应的内存溢出异常,会在目录下形成一个异常时候的内存dump文件(如java_pid7126.hprof文件),将这个文件使用Memory Analyse Tool工具打开就可以看到当前dump内存空间的分析内容。
-XX:+HeapDumpOnCtrlBreak:
-Xss: 设置虚拟机栈内存容量
获得转储文件的一些方法:
- 使用JVM启动时的参数设置,如需要在内存溢出时才获取Dump可以使用
-XX:+HeapDumpOnOutOfMemoryError或者是希望在某个特定时间获取可以使用-XX:+HeapDumpOnCtrlBreak。 - 使用一些Java工具获取 ,如 JMap,JConsole 都可以帮助我们得到一个堆转储文件。
MAT工具的一些使用心得:
文件目录
使用MAT工具打开获取的java_pid7126.hprof文件后,会自动的形成如下的文件目录:
java_pid7126.a2s.index
java_pid7126.domIn.index
java_pid7126.domOut.index
java_pid7126.hprof //转储堆文件
java_pid7126.idx.index
java_pid7126.inbound.index
java_pid7126.index
java_pid7126.o2c.index
java_pid7126.o2hprof.index
java_pid7126.o2ret.index
java_pid7126.outbound.index
java_pid7126.threads
java_pid7126_Leak_Suspects.zip //打包的报告,解压后会形成一个有HTML方式的报告发送给其他人,方便读取
分析方法
分析三步曲:
- 对问题发生时刻的系统内存状态获取一个整体印象。
- 找到最有可能导致内存泄露的元凶,通常也就是消耗内存最多的对象
- 进一步去查看这个内存消耗大户的具体情况,看看是否有什么异常的行为。
具体的分析:
查看报告一:内存消耗的整体状况
在OverView上的Report中可以选择 Leak Suspects ,来查看整体对象消耗。下方有一个警告可以看到当前系统自动帮忙分析的怀疑对象。在这个怀疑对象中便可以发现大多数的问题。
查看报告二:分析问题的所在
分析对象为什么没有被回收从而导致一直占用内存。采用根搜索算法来分析对象的事情情况。
点击报告一种怀疑对象的Detail,可以看到相应的具体分析报告。
Shortest Paths To the Accumulation Point 分析GC根元素到内存消耗聚集点的最短路径。
Accumulated Objects 查看具体的内存对象信息。
几种经常出现的内存溢出方式
Java堆溢出
异常信息: "java.lang.OutOfMemoryError"。会跟着进一步提示Java heap space.
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid1293.hprof ...
Heap dump file created [27559990 bytes in 0.233 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:2245)
at java.util.Arrays.copyOf(Arrays.java:2219)
at java.util.ArrayList.grow(ArrayList.java:242)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:216)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:208)
at java.util.ArrayList.add(ArrayList.java:440)
at com.valentine.jvm.analyzer.exception.HeapOOM.main(HeapOOM.java:16)
Java堆溢出内存问题分析步骤总结:
- dump出来堆转储快照
- 使用MAT工具对dump出来的堆转储快照进行分析,重点是确认内存中得对象是否必要的,这样可以分清楚到底是出现了内存泄露(Memory Leak)还是内存溢出(Memory Overflow)
- 如果是内存泄露,进一步通过MAT工具分析泄露对象到GC Roots的引用链。找到泄露对象是通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收的。
- 如果不存在泄露,那么就是内存中得对象却是都还必须活着,就应当检查虚拟机的堆参数(-Xmx与-Xms),与机器物理内存对比看是否可以调大,从代码上检查是否存在某些对象生命周期过长、持有状态时间过长的情况,尝试减少程序运行期间的内存。
虚拟机和本地方法栈溢出
在HotSpot虚拟机中并不区分虚拟机栈和本地方法栈。到对于HostSpot来说-Xoss参数(设置本地方法栈大小)是存在的,但实际是无效的,栈容量只由-Xss参数决定。
异常情况:
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常
- 如果虚拟机在扩展栈时无法申请到足够的内存空间时,将抛出OutOfMemoryError异常
异常信息:
stack length:1891Exception in thread "main"
java.lang.StackOverflowError
at com.valentine.jvm.analyzer.exception.JavaVmStackSOF.stackLeak(JavaVmStackSOF.java:8)
at com.valentine.jvm.analyzer.exception.JavaVmStackSOF.stackLeak(JavaVmStackSOF.java:9)
at com.valentine.jvm.analyzer.exception.JavaVmStackSOF.stackLeak(JavaVmStackSOF.java:9)
……
at com.valentine.jvm.analyzer.exception.JavaVmStackSOF.stackLeak(JavaVmStackSOF.java:9)
在单线程下,无论是由于栈帧太小还是虚拟机栈容量太小,当内存无法分配的时候,虚拟机抛出的都是StackOverflowError异常。
在多线程下,通过不断的建立线程的方式可以产生内存溢出OutOfMemoryError异常。
在多线程情况下,给每个线程分配的内存越大,越容易产生内存溢出异常。由于操作系统分配给每个进程的内存是有限的,32位的Windows限制为2GB。虚拟机提供了参数来控制Java堆和方法区的这两部分内存的最大值。剩余的2GB减去Xmx,再减去MaxPermSize,忽略掉很小的程序计数器内存。如果虚拟机进程本身耗费的内存不计算,剩下的内存就是有虚拟机栈和本地方法栈瓜分了。此时如果每个线程分配到的虚拟机栈容量越大,可以建立的线程数量自然就越少,建立线程时就越容易把剩下的内存耗尽。
如果建立过多线程导致的内存溢出,在不能减少线程数或者更换64位虚拟机的情况下,就只能通过减少最大堆或者减少栈容量来获取更多的线程。
出现StackOverflowError的时候有错误堆栈可以读,即时加入+HeapDumpOnOutOfMemoryError也不会dump异常堆内存。
运行时常量池溢出
如果要项运行时常量池中添加内容,最简单的方法就是使用String.intern()这个Native方法。
异常信息:
java.lang.OutOfMemoryError: PermGen space
Dumping heap to java_pid1582.hprof ...
Heap dump file created [625411 bytes in 0.018 secs]
Exception in thread "Reference Handler" Error occurred during initialization of VM
java.lang.OutOfMemoryError: PermGen space
<<no stack trace available>>
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "Reference Handler"
从异常中可以看出OutOfMemoryError后报的是PermGen space,说明是方法区溢出。
方法区溢出
方法区用于存放Class的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。当大量的类产生时填满方法区,会造成方法去溢出。
方法区溢出也是一种常见内存溢出异常,一个类如果要被垃圾收集器回收,判断条件非常苛刻。
本机直接内存溢出
DirectMemory容量可通过-XX:MaxDirectMemorySize指定,如果不指定,则默认与Java堆的最大值(-Xmx)一样。
eclipse 插件汇总
eclipse 插件汇总
Eclipse Memory Analyzer Tool (MAT)
Help -> Install new Software -> 根据不同的eclipse版本选择,如我得Juno版本选择 Work with: Juno - http://download.eclipse.org/releases/juno -> General Purpose Tools -> 勾选 Memory Analyzer 和 Memory Analyzer(Charts) ->确定后完成安装,自动重启Eclipse后生效。
java activiti 实例工程maven实现
特殊依赖
activiti-common-rest 工程
maven-restlet
Public online Restlet repository
http://maven.restlet.org
activiti-explorer 工程
vaadin-addons
http://maven.vaadin.com/vaadin-addons
activiti-modeler 工程
maven-restlet
Public online Restlet repository
http://maven.restlet.org
activiti-mule 工程
mulesoft-releases
MuleSoft Releases Repository
http://repository.mulesoft.org/releases/
default
activiti-rest 工程
maven-restlet
Public online Restlet repository
http://maven.restlet.org
activiti-webapp-explorer2 工程
vaadin-addons
http://maven.vaadin.com/vaadin-addons
mac环境下安装eclipse以及相关插件
导读
在mac下得eclipse版本和windows下的eclipse还是有许多区别的。一些插件的依赖不一样。
之前使用kapler版本,下载maven插件之后,用起来总是会报各种奇奇怪怪的问题,今天有空下了一个juno版本,问题就解决了,也在这里记录一下相应的配置。
下载安装eclipse
下载地址http://www.eclipse.org/downloads/
最好选择javaEE版本,否则建不了web工程,选择Eclipse IDE for Java EE Developers。
安装完成后本地解压就可以了
安装maven插件
安装maven插件
Eclipse -> Help -> Install New Software
Add a new software site:
http://download.eclipse.org/technology/m2e/releases
通过这个链接安装的是maven eclipse插件的1.5版本。 可以展开版本选择需要的版本安装。
在mac下的eclipse直接通过这种方法安装,会报一个缺少slf4j依赖的错,用下面方法可以解决。
安装slf4j-api 插件
安装maven插件的时候会报一个依赖slf4j的依赖,下载方法为
Eclipse -> Help -> Install New Software
Add a new software site:
Name: slf4j
Url: http://www.fuin.org/p2-repository/
Expand "Maven osgi-bundles" and select "slf4j-api"
Click "Next" and follow the installation.
直接安装maven 1.3 版本
如果安装1.5版本一直出问题,可以选择安装maven的1.3版本,在mac的eclipse下就补需要别的插件补丁了。
Eclipse -> Help -> Install New Software
Add a new software site:
http://download.eclipse.org/technology/m2e/releases/1.3
配置maven
具体配置方法参考这里
Copyright © 2020 鄂ICP备16010598号-1