LInux查看文件夹大小
du命令参数详解见:http://baike.baidu.com/view/43913.htm
下面我们只对其做简单介绍;
查看linux文件目录的大小和文件夹包含的文件数
统计总数大小
du -sh filename(其实我们经常用du -sh *,显示当前目录下所有的文件及其大小,如果要排序再在后面加上 | sort -n)
du -sm * | sort -n 统计当前目录大小 并按大小 排序
du -sk * | sort -n
du -sk * | grep filename 查看一个文件夹的大小
du -m | cut -d "_" -f 2 /_看第二个/ 字符前的文字
查看此文件夹有多少文件 **/* 有多少文件
du filename/
du filename*/ |wc -l
40752
解释:
wc [-lmw]
参数说明:
-l :多少行
-m:多少字符
-w:多少字
或者也可以打开Nautilus窗口(文件夹首选项),点击“编辑”-“首选项”,切换到“显示”标签,改变“图标标题”下面的树形列表的内容为“大小,修改日期、类型”。设置立即生效。现在在文件图标的下面会显示文件的大小。
PS:
df -hl 查看磁盘剩余空间
du -sm文件夹
返回该文件夹总M数
更多功能查看:
df --help
du --help
du --help
用法:du [选项]... [文件]...
总结每个<文件>的磁盘用量,目录则取总用量。
长选项必须用的参数在使用短选项时也是必须的。
-a, --all write counts for all files, not just directories
--apparent-size print apparent sizes, rather than disk usage; although
the apparent size is usually smaller, it may be
larger due to holes in (sparse') files, internal--apparent-size --block-size=1'
fragmentation, indirect blocks, and the like
-B, --block-size=SIZE use SIZE-byte blocks
-b, --bytes equivalent to
-c, --total produce a grand total
-D, --dereference-args dereference FILEs that are symbolic links
-H like --si, but also evokes a warning; will soon
change to be equivalent to --dereference-args (-D)
-h, --human-readable print sizes in human readable format (e.g., 1K 234M 2G)
--si like -h, but use powers of 1000 not 1024
-k like --block-size=1K
-l, --count-links count sizes many times if hard linked
-L, --dereference dereference all symbolic links
-P, --no-dereference don't follow any symbolic links (this is the default)
-0, --null end each output line with 0 byte rather than newline
-S, --separate-dirs do not include size of subdirectories
-s, --summarize display only a total for each argument
-x, --one-file-system skip directories on different filesystems
-X FILE, --exclude-from=FILE Exclude files that match any pattern in FILE.
--exclude=PATTERN Exclude files that match PATTERN.
--max-depth=N print the total for a directory (or file, with --all)
only if it is N or fewer levels below the command
line argument; --max-depth=0 is the same as
--summarize
--help 显示此帮助信息并离开
--version 显示版本信息并离开
eg: du -smh oracle
54G 显示oracle文件夹的大小为54G
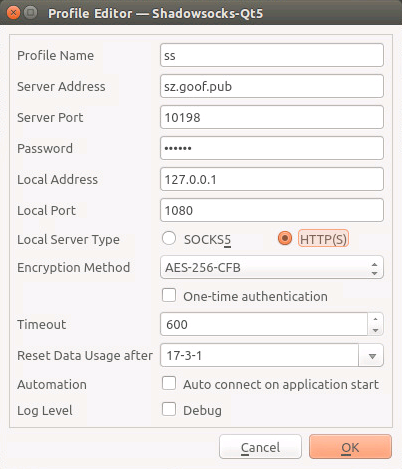
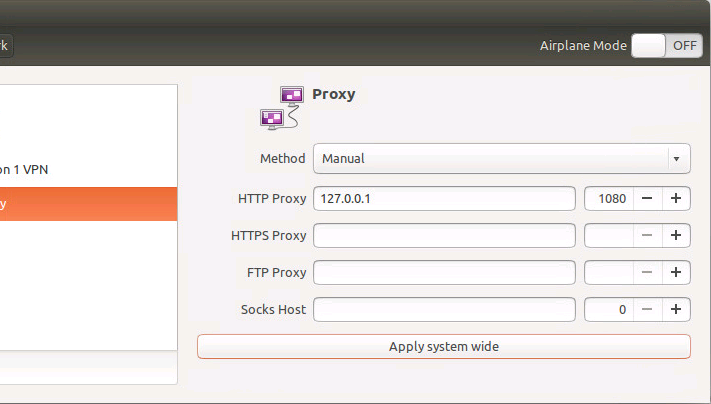
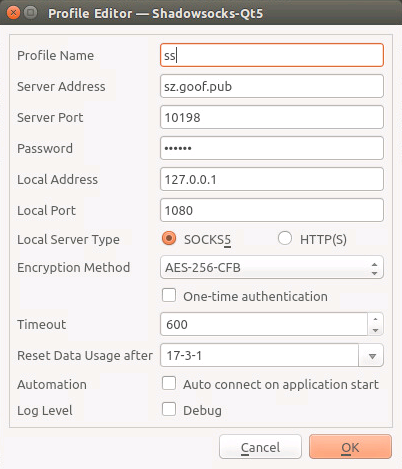
Ubuntu配置L2TP VPN
报错
通过ipsec verify 会出现报错,这里是因为多个网卡造成的,官方有帮助
https://lists.openswan.org/pipermail/users/2009-September/017423.html
http://askubuntu.com/questions/337036/openswans-ipsec-verify-fails-on-two-or-more-interfaces-found-checking-ip-forw
大概意思是多网卡的时候,对子网的检测会出现问题,这里可以忽略
只要 cat _proc_sys_net_ipv4/ip_forward 返回结果是1就没事
Checking your system to see if IPsec got installed and started correctly:
Version check and ipsec on-path [OK]
Linux Openswan U2.6.38/K3.19.0-25-generic (netkey)
Checking for IPsec support in kernel [OK]
SAref kernel support [N/A]
NETKEY: Testing XFRM related proc values [OK]
[OK]
[OK]
Checking that pluto is running [OK]
Pluto listening for IKE on udp 500 [OK]
Pluto listening for NAT-T on udp 4500 [OK]
Two or more interfaces found, checking IP forwarding [FAILED]
Checking NAT and MASQUERADEing [OK]
Checking for 'ip' command [OK]
Checking _bin_sh is not _bin_dash [WARNING]
Checking for 'iptables' command [OK]
Opportunistic Encryption Support [DISABLED]
折腾了一圈还是有点问题,下回专门来弄一下
Copyright © 2020 鄂ICP备16010598号-1