Scrapy基于Spider还提供了一个CrawlSpier类。通过这个类,我们只需少量代码就可以快速编写出强大且高效的爬虫。为更好使用CrawlSpider,我们需要深入到源码层面,在这篇文章中我将给出CrawlSpiderAPI的详细介绍,建议学习的时候结合源码。
目录
scrapy.spider.CrawlSpider类
- 创建CrawlSpider模板
- CrawlSpider类的属性和方法
- 实际运用中可以自己重写的属性/方法(重点)
scrapy.spider.Rule类
- Rule类的常用参数介绍
- 实际运用中最常用参数(重点)
LxmlLinkExtractor(LinkExtractor)类
- LinkExtractor类的常用参数介绍:
- 实际运用中最常用参数(重点)
scrapy.spider.CrawlSpider类
CrawlSpider是Scrapy最常见的用于爬取规则结构网页的类,它定义了一些规则用于从当前网页解析出其他网页。
创建CrawlSpider模板
在Scrapy工程的Spider文件夹下使用命令scrapy genspider -t crawl spider_name domain创建CrawlSpider爬虫。
创建好之后,会得到如下的模板(下面代码以爬取http://quotes.toscrape.com/为例)
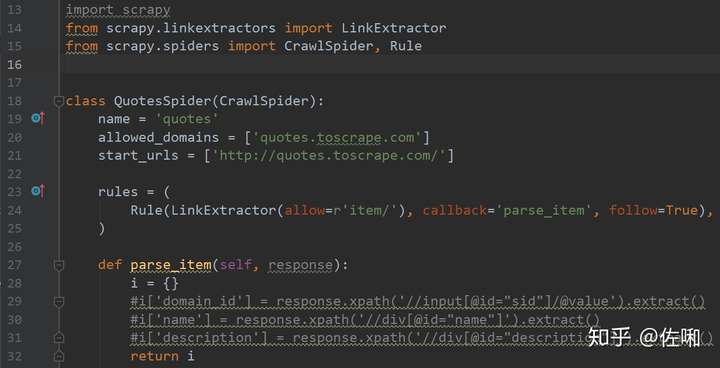
CrawlSpider类的属性和方法
类属性
- rules:它是一个包含若干个Rule实例对象的列表,其中每个Rule对象(后面会介绍)定义了爬取一个网页的具体规则。当多个规则匹配同一个链接时,只有第一个规则会生效。(
Rule对象将在下面做详细介绍)
- rules:它是一个包含若干个Rule实例对象的列表,其中每个Rule对象(后面会介绍)定义了爬取一个网页的具体规则。当多个规则匹配同一个链接时,只有第一个规则会生效。(
方法(建议结合源码理解)
- _parse_response(self, response, callback, cb_kwargs, follow=True):该方法是
CrawlSpider类的核心方法,该方法有两个功能:一,调用回调函数(parse_start_url())处理response。二,调用 _requests_to_follow()方法从当前网页中构建新的请求。
- parse(self, response):该方法重载了
Spider类的parse()方法。是CrawlSpider类获得Response后第一个执行的方法。这个方法将调用_parse_response()方法,由于_parse_response()方法中执行了回调函数和规则。因此,不能重写这个方法! - parse_start_url(self, response):该方法接收
start_url列表中url的response(起始请求),返回一个Item对象、Request对象或是它们的可迭代类型。作为回调函数,它传递给_parse_response()方法,根据需求,可进行重载。其作用相当于Spider类中的parse()方法。 - process_results(self, response, results):该方法用于加工parse_start_url方法返回的结果,可重载。
- _requests_to_follow(self, response):该方法根据
rule中的规则构建相应request。
- _parse_response(self, response, callback, cb_kwargs, follow=True):该方法是
注意:
- 不同于
Spider类,CrawlSpider类中定义的parse方法有特殊作用,因此在继承CrawlSpider的子类中不能重写该方法!
- 不同于
实际运用中可以自己重写的属性/方法(重点)
rulesparse_start_url()process_results()
scrapy.spider.Rule类
API:class scrapy.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
Rule类的常用参数介绍:
- link_extractor:它是一个
LinkExtractor对象(下面将介绍),定义从当前网页获取新的链接的规则。 - callback:它接收一个回调函数(定义当前类中)的名称(注意,是函数的名称而不是引用),之后用于处理按照
link_extractor提取到的链接的Response。该回调函数接收response作为其第一个参数,返回Item、Request或它们的子类。需要注意的是,parse方法不能作为回调函数。(这和Spider类中的情况不一样!) - cb_kwargs:它是一个参数字典,传递给回调函数。
- follow:它是一个bool类型,用于指定是否要继续从当前规则解析出的Response中提取链接。如果
callback是None,则follow默认为True,否则默认为False。 - process_links:它接收一个回调函数(定义当前类中)的名称(注意,是函数的名称而不是引用),用于进一步处理那些用规则提取出的链接。
- process_request:它接收一个回调函数(定义当前类中)的名称(注意,是函数的名称而不是引用),用于处理使用当前规则的request。
实际运用中最常用参数(重点)
link_extractorcallbackfollow
LxmlLinkExtractor(LinkExtractor)类
LinkExtractor类用于从网页(Response)中提取匹配模式(由正则表达式定义)的链接。它拥有一个extract_links方法,该方法接收一个Respose,并且返回scrapy.link.Link对象的列表。每个LinkExtractor类只被实例化依一次,但是它们的extract_links方法会被多次调用以提取不同的Response的链接。
在Scrapy中,LxmlLinkExtractor被声明为LinkExtractor,习惯上用后者称呼前者。
API:class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(), tags=('a', 'area'), attrs=('href', ), canonicalize=False, unique=True, process_value=None, strip=True)
LinkExtractor类的常用参数介绍:
- allow:定义待提取的链接的模式。它接收一个正则表达式串或是正则表示式的串序列。默认则提取所有链接。
- deny:类似allow参数,区别只在于该参数匹配到链接都不提取。其优先级高于allow。默认无效。
- allow_domains:它是一个字符串或字符串序列,限定满足哪些域名的网页可以被提取。
- deny_domains:类似allow_domains,功能相反。
- restrict_xpaths:它是一个Xpath字符串或字符串序列,定义了网页中提取链接的特定区域。定义该参数后,只有满足Xpath的网页特定区域内可以提取到链接。
- restrict_css:功能类似restrict_xpaths。
- tags:它是一个字符串或字符串序列,定义了网页链接的标签来源。默认为
('a', 'area')。 - attrs:它是一个字符串或字符串序列,定义了网页链接的属性来源(必须是满足tags参数规定的标签的属性)。默认为
('href',)。 - process_value:它是一个回调函数,可以对提取到的值(源于tags和attrs)做进一步处理(例如:从JavaScript代码进一步提取出真实的url)。
实际运用中最常用参数(重点)
allowallow_domainsrestrict_xpathsrestrict_csstagsattrs