python 日志类
Python + logging 输出到屏幕,将log日志写入文件
日志
日志是跟踪软件运行时所发生的事件的一种方法。软件开发者在代码中调用日志函数,表明发生了特定的事件。事件由描述性消息描述,该描述性消息可以可选地包含可变数据(即,对于事件的每次出现都潜在地不同的数据)。事件还具有开发者归因于事件的重要性;重要性也可以称为级别或严重性。
logging提供了一组便利的函数,用来做简单的日志。它们是 debug()、 info()、 warning()、 error() 和 critical()。
logging函数根据它们用来跟踪的事件的级别或严重程度来命名。标准级别及其适用性描述如下(以严重程度递增排序):
| 级别 | 何时使用 |
|---|---|
DEBUG |
详细信息,一般只在调试问题时使用。 |
INFO |
证明事情按预期工作。 |
WARNING |
某些没有预料到的事件的提示,或者在将来可能会出现的问题提示。例如:磁盘空间不足。但是软件还是会照常运行。 |
ERROR |
由于更严重的问题,软件已不能执行一些功能了。 |
CRITICAL |
严重错误,表明软件已不能继续运行了。 |
| 级别 | 数字值 |
|---|---|
CRITICAL |
50 |
ERROR |
40 |
WARNING |
30 |
INFO |
20 |
DEBUG |
10 |
NOTSET |
0 |
默认等级是WARNING,这意味着仅仅这个等级及以上的才会反馈信息,除非logging模块被用来做其它事情。
被跟踪的事件能以不同的方式被处理。最简单的处理方法就是把它们在控制台上打印出来。另一种常见的方法就是写入磁盘文件。
一、打印到控制台
import logging
logging.debug('debug 信息')
logging.warning('只有这个会输出。。。')
logging.info('info 信息')
由于默认设置的等级是warning,所有只有warning的信息会输出到控制台。
WARNING:root:只有这个会输出。。。
利用logging.basicConfig()打印信息到控制台
import logging
logging.basicConfig(format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s',
level=logging.DEBUG)
logging.debug('debug 信息')
logging.info('info 信息')
logging.warning('warning 信息')
logging.error('error 信息')
logging.critical('critial 信息')
由于在logging.basicConfig()中的level 的值设置为logging.DEBUG, 所有debug, info, warning, error, critical 的log都会打印到控制台。
日志级别: debug < info < warning < error < critical
logging.debug('debug级别,最低级别,一般开发人员用来打印一些调试信息')
logging.info('info级别,正常输出信息,一般用来打印一些正常的操作')
logging.warning('waring级别,一般用来打印警信息')
logging.error('error级别,一般用来打印一些错误信息')
logging.critical('critical 级别,一般用来打印一些致命的错误信息,等级最高')
所以如果设置level = logging.info()的话,debug 的信息则不会输出到控制台。
二、利用logging.basicConfig()保存log到文件
logging.basicConfig(level=logging.DEBUG,#控制台打印的日志级别
filename='new.log',
filemode='a',##模式,有w和a,w就是写模式,每次都会重新写日志,覆盖之前的日志
#a是追加模式,默认如果不写的话,就是追加模式
format=
'%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'
#日志格式
)
如果在logging.basicConfig()设置filename 和filemode,则只会保存log到文件,不会输出到控制台。
三、既往屏幕输入,也往文件写入log
logging库采取了模块化的设计,提供了许多组件:记录器、处理器、过滤器和格式化器。
- Logger 暴露了应用程序代码能直接使用的接口。
- Handler将(记录器产生的)日志记录发送至合适的目的地。
- Filter提供了更好的粒度控制,它可以决定输出哪些日志记录。
- Formatter 指明了最终输出中日志记录的布局。
Loggers:
Logger 对象要做三件事情。首先,它们向应用代码暴露了许多方法,这样应用可以在运行时记录消息。其次,记录器对象通过严重程度(默认的过滤设施)或者过滤器对象来决定哪些日志消息需要记录下来。第三,记录器对象将相关的日志消息传递给所有感兴趣的日志处理器。
常用的记录器对象的方法分为两类:配置和发送消息。
这些是最常用的配置方法:
Logger.setLevel()指定logger将会处理的最低的安全等级日志信息, debug是最低的内置安全等级,critical是最高的内建安全等级。例如,如果严重程度为INFO,记录器将只处理INFO,WARNING,ERROR和CRITICAL消息,DEBUG消息被忽略。
Logger.addHandler()和Logger.removeHandler()从记录器对象中添加和删除处理程序对象。处理器详见Handlers。
Logger.addFilter()和Logger.removeFilter()从记录器对象添加和删除过滤器对象。
Handlers
处理程序对象负责将适当的日志消息(基于日志消息的严重性)分派到处理程序的指定目标。Logger 对象可以通过addHandler()方法增加零个或多个handler对象。举个例子,一个应用可以将所有的日志消息发送至日志文件,所有的错误级别(error)及以上的日志消息发送至标准输出,所有的严重级别(critical)日志消息发送至某个电子邮箱。在这个例子中需要三个独立的处理器,每一个负责将特定级别的消息发送至特定的位置。
常用的有4种:
1) logging.StreamHandler -> 控制台输出
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。
它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler -> 文件输出
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler -> 按照大小自动分割日志文件,一旦达到指定的大小重新生成文件
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler -> 按照时间自动分割日志文件
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
配置方法:
setLevel()方法和日志对象的一样,指明了将会分发日志的最低级别。为什么会有两个setLevel()方法?记录器的级别决定了消息是否要传递给处理器。每个处理器的级别决定了消息是否要分发。setFormatter()为该处理器选择一个格式化器。addFilter()和removeFilter()分别配置和取消配置处理程序上的过滤器对象。
Formatters
Formatter对象设置日志信息最后的规则、结构和内容,默认的时间格式为%Y-%m-%d %H:%M:%S,下面是Formatter常用的一些信息
| %(name)s | Logger的名字 |
|---|---|
| %(levelno)s | 数字形式的日志级别 |
| %(levelname)s | 文本形式的日志级别 |
| %(pathname)s | 调用日志输出函数的模块的完整路径名,可能没有 |
| %(filename)s | 调用日志输出函数的模块的文件名 |
| %(module)s | 调用日志输出函数的模块名 |
| %(funcName)s | 调用日志输出函数的函数名 |
| %(lineno)d | 调用日志输出函数的语句所在的代码行 |
| %(created)f | 当前时间,用UNIX标准的表示时间的浮 点数表示 |
| %(relativeCreated)d | 输出日志信息时的,自Logger创建以 来的毫秒数 |
| %(asctime)s | 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
| %(thread)d | 线程ID。可能没有 |
| %(threadName)s | 线程名。可能没有 |
| %(process)d | 进程ID。可能没有 |
| %(message)s | 用户输出的消息 |
需求:
输出log到控制台以及将日志写入log文件。
保存2种类型的log, all.log 保存debug, info, warning, critical 信息, error.log则只保存error信息,同时按照时间自动分割日志文件。
import logging
from logging import handlers
class Logger(object):
level_relations = {
'debug':logging.DEBUG,
'info':logging.INFO,
'warning':logging.WARNING,
'error':logging.ERROR,
'crit':logging.CRITICAL
}#日志级别关系映射
def __init__(self,filename,level='info',when='D',backCount=3,fmt='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'):
self.logger = logging.getLogger(filename)
format_str = logging.Formatter(fmt)#设置日志格式
self.logger.setLevel(self.level_relations.get(level))#设置日志级别
sh = logging.StreamHandler()#往屏幕上输出
sh.setFormatter(format_str) #设置屏幕上显示的格式
th = handlers.TimedRotatingFileHandler(filename=filename,when=when,backupCount=backCount,encoding='utf-8')#往文件里写入#指定间隔时间自动生成文件的处理器
#实例化TimedRotatingFileHandler
#interval是时间间隔,backupCount是备份文件的个数,如果超过这个个数,就会自动删除,when是间隔的时间单位,单位有以下几种:
# S 秒
# M 分
# H 小时、
# D 天、
# W 每星期(interval==0时代表星期一)
# midnight 每天凌晨
th.setFormatter(format_str)#设置文件里写入的格式
self.logger.addHandler(sh) #把对象加到logger里
self.logger.addHandler(th)
if __name__ == '__main__':
log = Logger('all.log',level='debug')
log.logger.debug('debug')
log.logger.info('info')
log.logger.warning('警告')
log.logger.error('报错')
log.logger.critical('严重')
Logger('error.log', level='error').logger.error('error')
屏幕上的结果如下:
2018-03-13 21:06:46,092 - D:/write_to_log.py[line:25] - DEBUG: debug
2018-03-13 21:06:46,092 - D:/write_to_log.py[line:26] - INFO: info
2018-03-13 21:06:46,092 - D:/write_to_log.py[line:27] - WARNING: 警告
2018-03-13 21:06:46,099 - D:/write_to_log.py[line:28] - ERROR: 报错
2018-03-13 21:06:46,099 - D:/write_to_log.py[line:29] - CRITICAL: 严重
2018-03-13 21:06:46,100 - D:/write_to_log.py[line:30] - ERROR: error
由于when=D,新生成的文件名上会带上时间,如下所示。




wechat-scrawle 配置指南记录
环境配置指南
1. 安装mongodb / redis / elasticsearch
安装MongoDB
具体的mongodb配置见下面这篇文章
安装redis
具体的安装redis参考这篇
redis 使用
安装elasticsearch
安装 elasticsearch-ik中文分词器
下载 elasticsearch-analysis-ik-5.1.1.zip (注意:和elasticsearch版本对应),直接下载其release的版本(第一个zip文件,避免maven打包)
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v5.1.1
(可以选一个比较新的版本下载)
在/Users/duhuifang/Downloads/elasticsearch-5.1.1/plugins下建立ik目录
mkdir ik
移动 elasticsearch-analysis-ik-5.1.1.zip至elasticsearch的plugins文件夹的ik文件夹下:
cp Downloads/ elasticsearch-analysis-ik-5.1.1.zip /Users/duhuifang/Downloads/elasticsearch-5.1.1/plugins/ik
解压文件
unzip elasticsearch-analysis-ik-5.1.1.zip
启动elasticsearch,即可看到加载了analysis-ik插件
完成之后可以使用postman进行测试
POST http://localhost:9200/_analyze
body
{
"analyzer":"ik_max_word",
"text":"中华人民共和国国歌"
}
2. Install proxy server and run proxy.js
使用npm安装anyproxy
3. 安装python包
起virtualenv环境
使用pip install -r requirements.txt 来安装
注意里面有个windows的依赖包可以删掉
4. 安装adb
安装android SDK,这里不多说了
安装NOX或者mumu,这里我安装的mumu,NOX现在微信不能访问了。
要起的哪几个内容
node proxy.js
redis-server /usr/local/etc/redis.conf
python3 ./main.py
sudo mongod
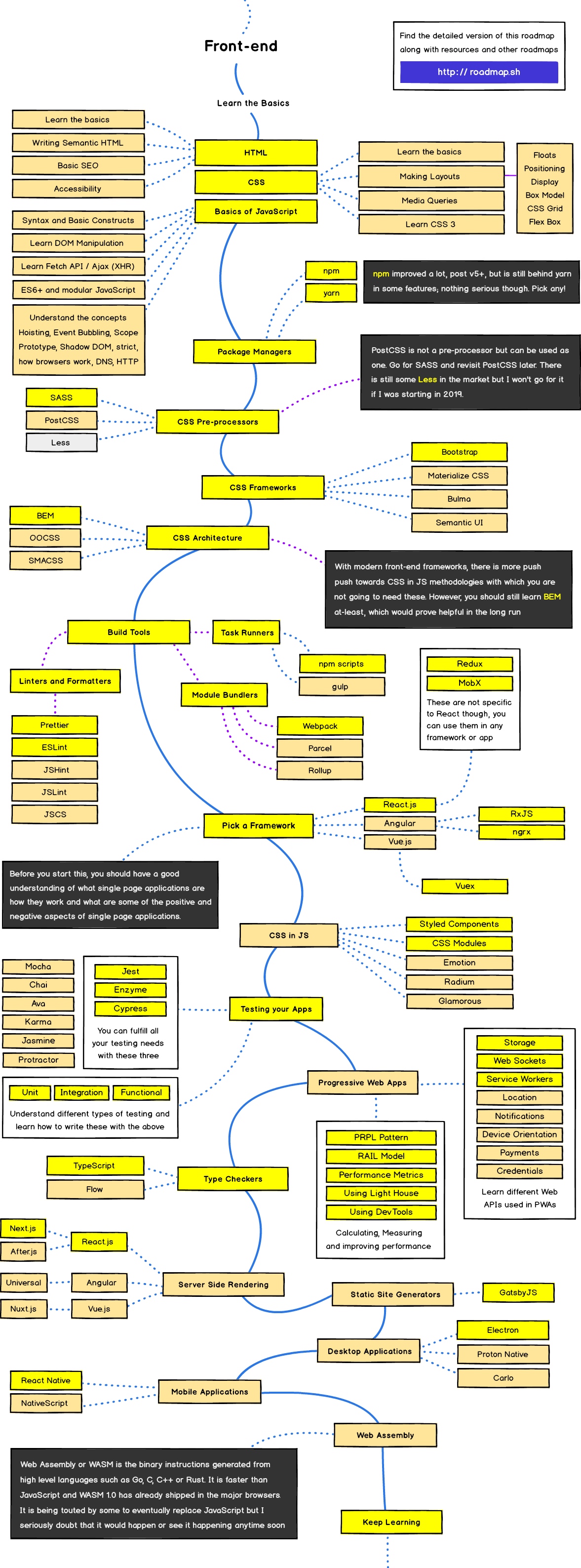
Modern Backend and Frontend Developer in 2018
Modern Backend Developer in 2018
后端语言学习路径
Modern Backend Developer in 2018

- 选择一门语言
- 写入门实践代码 —— 用最简单的方式最快的学习去实践如何写
- 学习包管理工具 —— python pip。 基本上每种语言都有包管理工具
- 了解语言的开发标准和开发规范 —— 比如python的PEP8或者black
- 自己写一些包或者去给一些包做分支 —— 可以自己写一些包去开源,做好之后可以给一些开源软件贡献代码
- 学习测试 —— 给自己的项目做单元测试和集成测试
- 写测试用例并使用到实践当中
- 学习关系数据库 —— 学习使用一种关系数据库
- 实践实践 —— 使用学到的所有东西创建一个应用,例如blog等
- 学习一个框架
- 学习一个NoSQL数据库 —— MongoDB
- 学习缓存 —— redis或者memcache
- 创建RestfulAPI
- Authentication 鉴权方式
- 学习消息队列 —— 知道为什么要使用消息队列,怎么使用
- 学习一个搜索引擎 —— ElasticSearch、sola
- 学习怎么使用docker
- 学习如何使用WebServer
- 学习如何使用Web Socket
- 学习 GraphQL
- 学习 Graph Database
- 学习其他部分 —— profilling, Static Analyse, DDD, SOAP 等等
- 持续学习
前端学习路径
Modern Frontend Developer in 2018
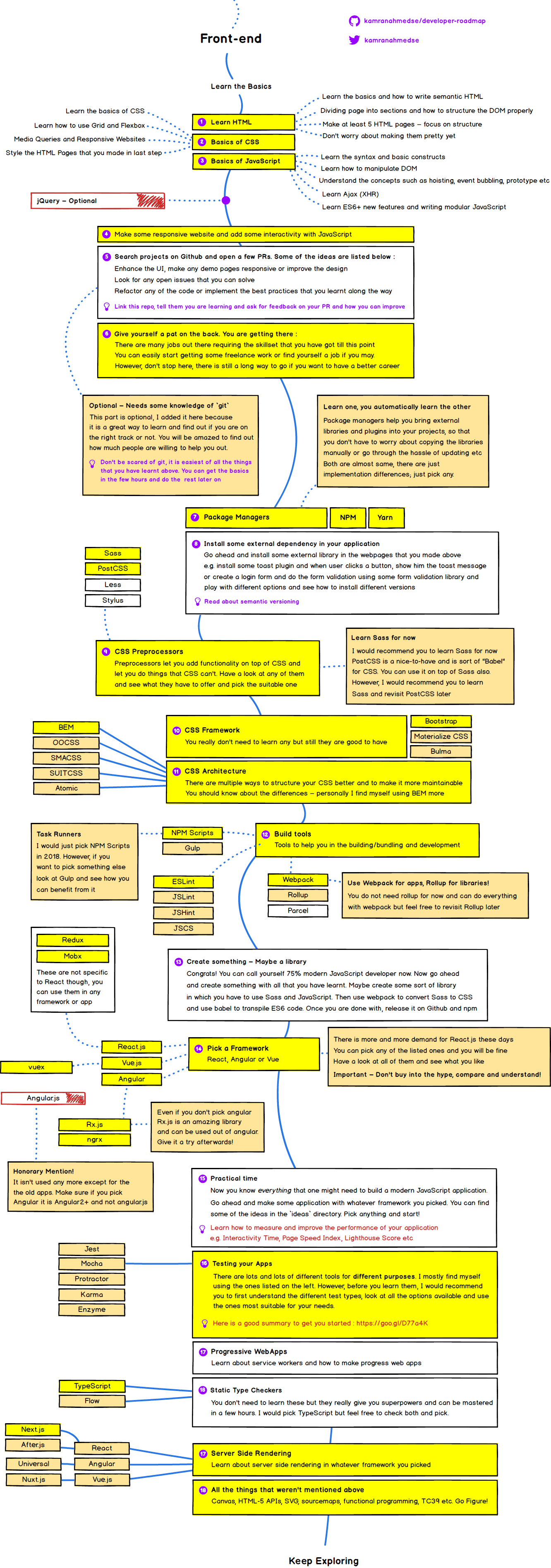
- 学习HTML
- CSS基础
- Javascript基础
- 使用javascript做一些交互式网站和一些简单的交互
- 在github上面找一个开源项目并提一些SR需求
- 为自己找一个合适职业
- 包管理 —— npm、yarn
- 为你的应用装一些第三方依赖
- CSS 预处理组件 —— Sass Less等
- 学习CSS框架 —— Bootstrap
- CSS架构 —— BEM
- 构建工具 —— webpack、NPM Scripts、 Gulp
- 做点东西 —— 简单的做一些实践
- 选一个框架 —— vue, react, angular
- 实践 —— 开始做一些小项目进行实践
- 测试你的APP ——
- progressive Webapps
- js静态检查 —— TypeScript
- 学习服务端渲染
- 学习其他内容 —— canvas, HTML-5, SVG, sourcemaps, functional programming等
- 持续学习
少儿编程
现在大多数平台的少儿编程教育都以scratch为基础平台来进行,无非就是在上面针对不同的部分进行二次开发。
类似西瓜创客的做法就是针对scratch做一个多少小时的培训,引导小朋友做出自己的相应的程序来进行发布,提升小朋友对于编程的喜爱,然后逐步的开放小朋友对于编程的热爱
scratch可以教会小朋友:
- 画画的能力
- 制作语音的能力
- 创意
- 基础的编程实现创意能力
kano
一个使用树莓派将儿童玩具作为议题的公司,软件类似使用scratch类似的模式,然后添加上一些sensor之类的内容。方便孩子所见即所得的获取编程快乐
爱湃森2018年度python榜单
python star 数最多的项目
awesome-python
系统设计教程
这是一个很好的教程,从这个教程可以学到几个东西
- 所有教程都形成了anki库,通过anki工具更方便后面的学习
- 各种不同系统的架构设计方式,包括各种不同的设计方式
Tensorflow modles
TensorFlow的一些不同模型的实现和一些样例教程,适合入门学习
public-apis
整理了线上的很多公共可以使用的API
awesome-machine-learning
机器学习的相关比较好的代码库
2018年最受欢迎的python项目
cerbot let's encrypt 用于全站https加密的网站
Detectron
facebook开源的机器学习动态监测API,使用python开发,使用caffe2深度学习框架
pipenv
pipenv 现在资料比较多了,可以好好整理一下
sanic
sanic一个新的异步框架
2018爬虫框架
- scrapy
- pyspider
- python-spider
- photon
- lianjia-scrawler
- Weixin-crawler 非常值得研究一下
- rula
- Instagram-scraper
- Weibo-Spider
- Haipproxy
2018年需要学习的python项目
black
Black号称不妥协的代码格式化工具,为什么叫不妥协呢?因为它检测到不符合规范的代码风格直接就帮你全部格式化好,根本不需要你确定,直接替你做好决定。它也是 requests 作者最喜欢的工具之一.使用非常简单,安装成功后,和其他系统命令一样使用,只需在 black 命令后面指定需要格式化的文件或者目录就ok。
在pycharm里面也可以集成black。
wtfpython
这个可以好好了解一下,python一些神奇的东西
photon
一个爬虫框架
python入门书籍


redash docker deploy
redash官方提供了基于docker下面的deploy文档,在目录setup下面。https://github.com/yourwilliam/redash/tree/master/setup
这份脚本是基于ubuntu18.04的,建议在ubuntu18下面进行安装部署
具体使用步骤如下:
1. 切换apt源
ubuntu18 版本安装完成之后发现里面并没有包含所有的官方源,最好是切换到国内的源,这样速度也更快。
修改/etc/apt/sources.list文件,记得最好把这个文件备份一个,方便后面修复。
中科大源
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
然后执行命令:
sudo apt-get update
sudo apt-get upgrade
也可以使用其他的源,如下
阿里源
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
163源
deb http://mirrors.163.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ bionic-backports main restricted universe multiverse
清华源
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
git clone 下载
注意脚本里面很多东西都写了绝对目录,默认认为redash在目录 /opt/redash下,所以也是在opt目录下面进行git clone可以指定到对应的路径下。尽量不要自己修改目录,否则要修改的地方会很多。
执行setup/setup.sh文件
执行setup文件就可以安装
docker配置
在docker中检查当前网络状况要使用ping命令的时候,有时候由于没有安装无法使用,这时候可以自己安装
#1. 首先一定要更新源
apt-get update
#2. 安装工具包
apt-get install vim # 安装vim
apt-get install telnet # 安装telnet
apt-get install net-tools # 安装ifconfig
apt install iputils-ping # 安装ping
通过root进入docker容器
docker exec -i -t -u 0 e575dad3beae /bin/bash
# 其中e575dad3beae 通过docker ps获取
问题
问题1:
直接安装后,会出现一个权限不足的问题,页面无法访问
是由于在docker中执行npm build 和 npm start的时候是使用的redash用户,而不是root用户,所有数据库无法连接,同时很多文件没有权限访问
当前解决办法:
通过docker ps查询所在使用的容器实例,找到实例id。然后通过root进入到docker中执行命令docker exec -i -t -u 0 e575dad3beae /bin/bash,进去之后重新执行upm build 和 npm start即可。
问题2:
使用Nginx解析到5000端口之后无法登陆。
状态是访问 api目录的时候返回502.
返回结果,报错为:
It seems like we encountered an error. Try refreshing this page or contact your administrator.
使用docker-compose up看日志,没有看到系统的错误日志,返回都是200。那么应该是前端的错误。找到Nginx错误日志,返回以下结果:
2018/11/12 18:57:10 [error] 2002#0: *26219243 upstream sent too big header while reading response header from upstream, client: 61.183.143.20, server: bi2.hansap.com, request: "GET /api/organization/status HTTP/1.1", upstream: "http://*.*.*.*:5000/api/organization/status", host: "*******", referrer: "http://*******/"
从这里看那么就可以说明应该是Proxy配置问题,需要添加配置:
server {
listen 80;
server_name **********;
gzip on;
gzip_types *;
gzip_proxied any;
location / {
proxy_pass http://***.***.***.***:5000/;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $http_x_forwarded_proto;
#proxy_pass_request_body on;
client_max_body_size 100m;
proxy_redirect off;
proxy_buffer_size 64k;
proxy_buffers 32 32k;
proxy_busy_buffers_size 128k;
}
}
完成之后重新load就可以访问了。
问题3 配置邮件
开发环境的配置文件在 /opt/redash/.env 下,正式环境的配置文件在/opt/redash/env下
但是如果是docker安装,docker会默认读取docker的环境变量,所以在/opt/redash/env下的环境变量不会生效(不知道官网怎么这么写,害人啊) 具体的可以参看
官网 https://redash.io/help/open-source/setup 官网的作为参考,按这个配置不能生效
解决问题的帖子 https://discuss.redash.io/t/where-is-opt-redash-env/999
原因是docker的环境变量需要写在docker compose的配置文件内,内部才能读取。所以这里的env 仅仅只是一个参考,修改了也是没有效果的
具体配置如下:
# /opt/redash/docker-compose.yml文件
version: '2'
services:
server:
build: .
command: dev_server
depends_on:
- postgres
- redis
ports:
- "5000:5000"
volumes:
- ".:/app"
environment:
PYTHONUNBUFFERED: 0
REDASH_LOG_LEVEL: "INFO"
REDASH_REDIS_URL: "redis://redis:6379/0"
REDASH_DATABASE_URL: "postgresql://postgres@postgres/postgres"
REDASH_MAIL_SERVER: "smtp.hansap.com"
REDASH_MAIL_PORT: 25
REDASH_MAIL_USE_TLS: "false"
REDASH_MAIL_USE_SSL: "false"
REDASH_MAIL_USERNAME: "*****"
REDASH_MAIL_PASSWORD: "*****"
REDASH_MAIL_DEFAULT_SENDER: "hansap@hansap.com"
REDASH_HOST: "http://bi2.hansap.com"
worker:
build: .
command: scheduler
volumes_from:
- server
depends_on:
- server
environment:
PYTHONUNBUFFERED: 0
REDASH_LOG_LEVEL: "INFO"
REDASH_REDIS_URL: "redis://redis:6379/0"
REDASH_DATABASE_URL: "postgresql://postgres@postgres/postgres"
QUEUES: "queries,scheduled_queries,celery"
WORKERS_COUNT: 2
REDASH_MAIL_SERVER: "smtp.hansap.com"
REDASH_MAIL_PORT: 25
REDASH_MAIL_USE_TLS: "false"
REDASH_MAIL_USE_SSL: "false"
REDASH_MAIL_USERNAME: "******"
REDASH_MAIL_PASSWORD: "******"
REDASH_MAIL_DEFAULT_SENDER: "hansap@hansap.com"
REDASH_HOST: "http://bi2.hansap.com"
...
Copyright © 2020 鄂ICP备16010598号-1